
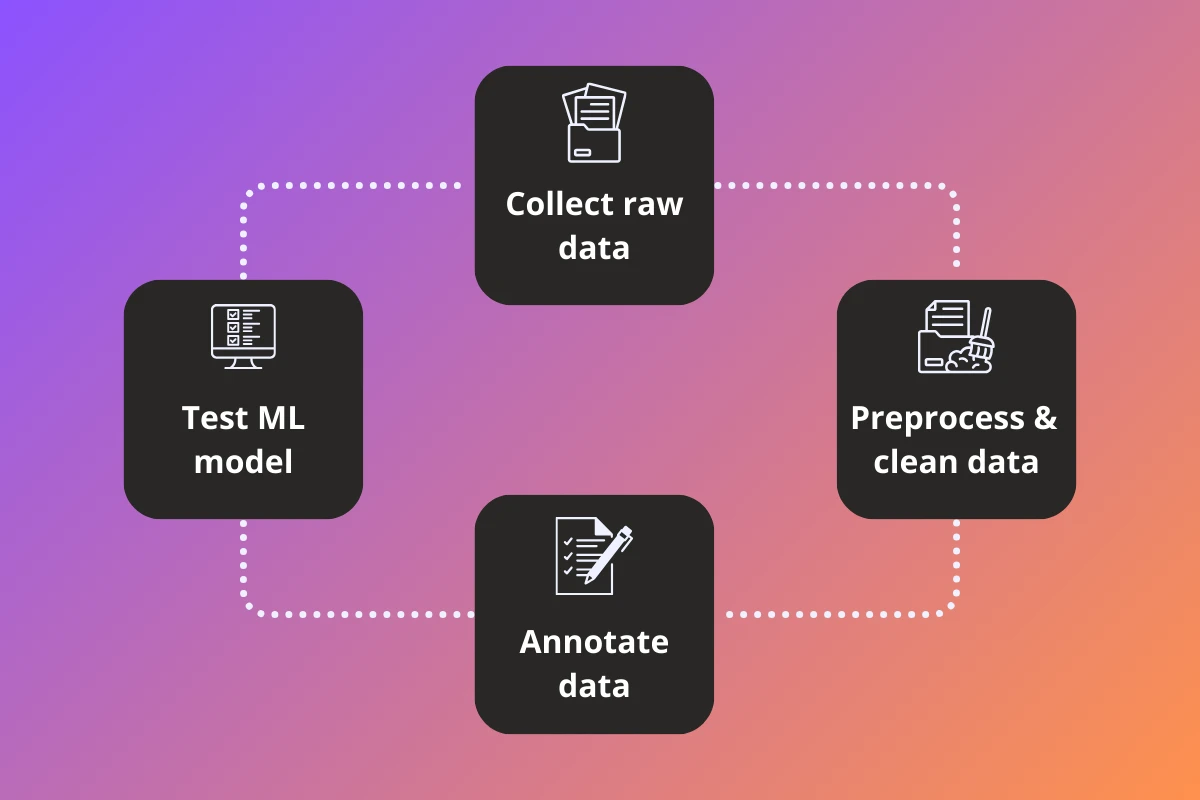
Introduction
The success of Machine Learning models heavily relies on the quality and diversity of the training data they are trained on. It stands to reason that collecting and preparing such training data is a crucial step in the development process of ML models. In this article we explore strategies for this activity, with the aim of ensuring that they are effective, accurate, and representative.
1. Define Clear Objectives and Use Cases
Before collecting training data, it is essential to have a clear understanding of the objectives and use cases of end Machine Learning model. This clarity will help in determining the specific data requirements and ensure that the collected data aligns with the intended purpose of the model. Clearly defining the objectives also aids in identifying the relevant data sources and potential biases to be addressed during the data collection and preparation phase.
2. Determine Data Sources
Identifying the appropriate data sources is crucial to ensure the availability of relevant and diverse training data. Depending on the Machine learning model's requirements, data sources can include structured databases, public datasets, web scraping, social media, user-generated content, sensor data, and more. It is essential to evaluate the reliability, quality, and legality of the selected data sources. In some cases, the only option is to capture the data yourself - for example, if your use-case utilizes special sensors like LIDARs or cameras in specific locations. However, at-least for the experimental stage, you can find enough data publicly available.
3. Dataset licenses

While there is a plethora of publicly available datasets today, it is important to note the licenses under which they are released. Some datasets may not be available for commercial purposes at all. Others might warrant permission to be granted by the dataset owner. Here are some commonly found dataset licenses.
- Public Domain: Datasets in the public domain are freely available to everyone for any use, without restriction.
- Creative Commons Zero (CC0): Very similar to the Public Domain license, but with some additional protections for the licensor, such as a waiver of moral rights.
- Open Data Commons Public Domain Dedication and License (ODC-PDDL): This license is specifically designed for datasets, and it is identical to the Public Domain.
- Creative Commons Attribution (CC BY): This license allows anyone to use, share, and adapt the dataset, as long as they give credit to the original creator.
- Open Data Commons Attribution License (ODC-BY): This license is similar to the CC BY license, but it is specifically designed for datasets.
- Creative Commons Attribution-NonCommercial (CC BY-NC): Allows users to copy, distribute, and modify the dataset, as long as they give credit to the original creator and do not use it for commercial purposes
4. Ensure Data Diversity and Representation
To develop robust and unbiased AI models, it is crucial to ensure that the training dataset is diverse and representative of the target population or the real-world scenarios the model will encounter. This includes considering factors such as demography, geographic locations, cultural backgrounds, and various perspectives. Proactively addressing underrepresented groups or potential biases helps in creating fair and inclusive AI models.
5. Data Cleaning and Preprocessing
Raw data often contains noise, inconsistencies, missing values, or outliers that can negatively impact AI model performance. Data cleaning and preprocessing techniques are applied to remove or correct these issues. This may involve removing duplicate records, standardizing formats, handling missing data, and outlier detection. Ensuring data cleanliness and integrity is essential to prevent biased or misleading results.
There are several open-source tools available today to help you with data cleaning. You can find some helpful tools in our list of open source tools in Data Centric AI.
6. Data Annotation and Labeling

Data annotation and labeling play a significant role once the dataset has been collected. Annotation involves the process of adding metadata or labels to the raw data, enabling ML models to understand and learn from it. Depending on the use-case, annotation can involve labeling images, categorizing text, marking objects in videos, or assigning sentiment scores. Annotation has become far more sophisticated today with AI being used to assist human annotators. This is results in datasets of much higher quality. You can learn more about our Data annotation services here.
7. Establish Data Privacy and Security Measures
Data privacy and security should be prioritized throughout the data collection and preparation process. Adequate measures must be in place to protect sensitive information, comply with relevant regulations (such as GDPR), and anonymize personal data if necessary.
8. Consider Ethical and Legal Implications
AI has the potential to impact individuals and society at large. It is important to consider the ethical and legal implications associated with the collection and use of training data. Respecting privacy rights, avoiding discriminatory biases, and ensuring compliance with ethical guidelines are essential to develop responsible AI.
9. Continuous Iteration and Improvement
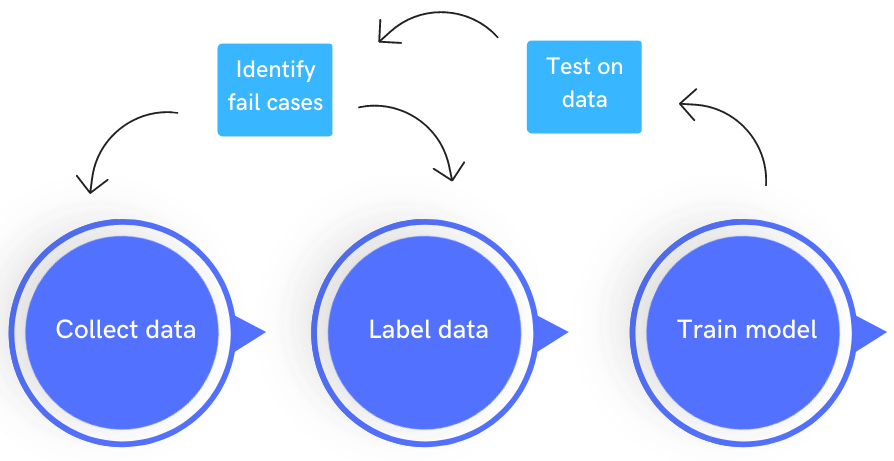
The process of collecting and preparing training data is not a one-time task. It requires continuous iteration and improvement. Feedback from AI model performance, user interactions, and real-world deployment should inform the refinement of training data. Updating and expanding the dataset over time helps the AI model stay relevant and adapt to changing conditions.
In recent years, there has been a growing shift from the traditional model-centric approach to improving ML performance to a more data-centric approach. The data centric approach to AI places importance on iteratively improving the data quality. This is a better approach to improving the Machine Learning model than trying to improve upon the algorithm, which in many cases, is already State of the art. You can learn more about Data Centric AI here.
Conclusion
Collecting and preparing high-quality training data is crucial for the success of ML models. By defining clear objectives, determining relevant data sources, ensuring data diversity and representation, cleaning and preprocessing data, and addressing privacy and ethical considerations, developers can create effective and unbiased AI systems. Continuous iteration and improvement further enhance the model's performance. By following these strategies, AI can be empowered with training data that drives accurate predictions, robust decision-making, and positive impacts on society.