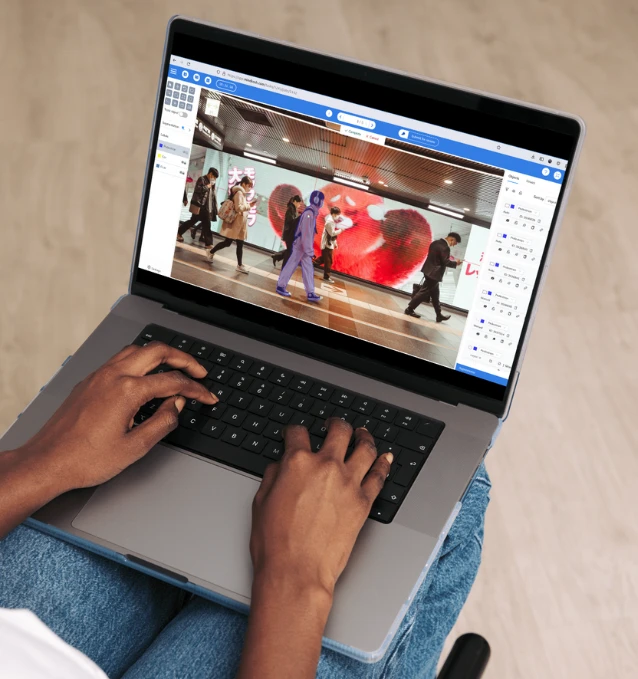
High quality data for all your Generative AI projects
Get highly accurate data for RLHF, prompt & response generation, LVMs and more.
Or use our services for testing and validating your Generative AI systems for safety and compliance.
Discuss your use caseHuman feedback for RLHF & more
Supercharge your language models by fine-tuning them with task-specific high quality human feedback.
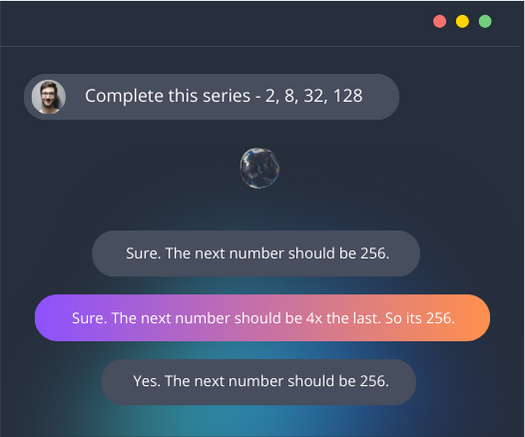
RLHF
Improve your model outputs with reinforcement learning combined with high quality response ratings.
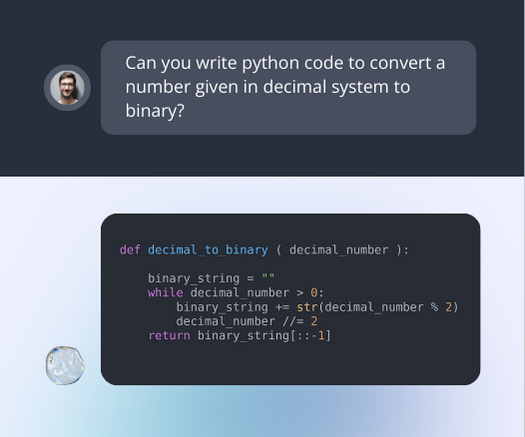
Supervised Fine-tuning
Adapt your model to your own use-case by training it on high quality human powered prompt responses.
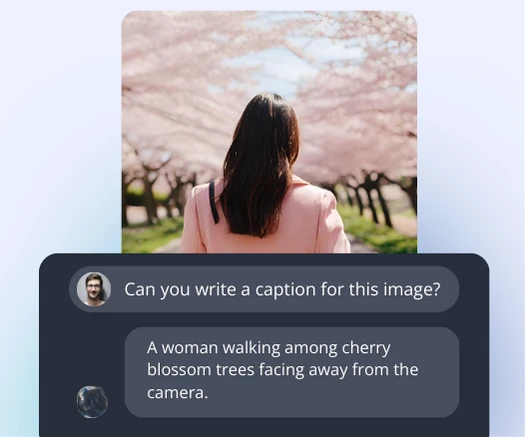
Image captioning
Fine-tune Generative AI models to your application with high quality image-caption pairs.
Testing and evaluation of LLMs.
Ensure high performance and safety of your models with hybrid testing and evaluation flows.
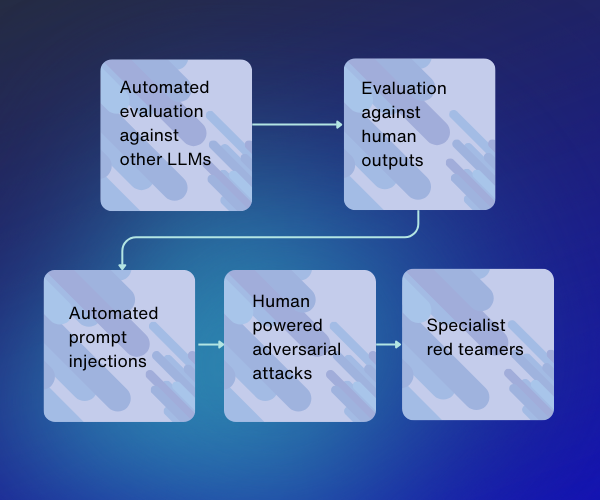
LLM model evaluation
Evaluate the performance of your model against SOTA LLMs as well as human-generated data.
Red teaming
Probe your model for undesirable behavior to assess safety and vulnerabilities. Combine automated attack techniques with human expertise to get the most scalable solution.
What are you
building?
Have a use-case in mind? Get in touch with us.
Chat with us
Call us
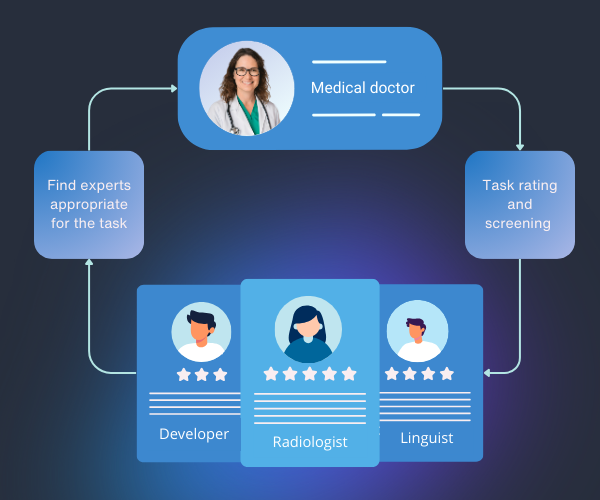
Need domain experts? No problem.
Leverage our diverse network of experts to deliver high quality datasets or perform testing and evaluation of your LLMs in any domain.
Get a custom quote for your annotation project