

Image Segmentation plays a crucial role in computer vision to understand the visual world. Instance segmentation and semantic segmentation are the two most widely used methods to perform image segmentation - each with distinct purposes and methodologies. In this article, we will try to understand both instance segmentation and semantic segmentation, highlighting their differences, technical aspects, and real-world applications.
What is Semantic Segmentation?
Semantic segmentation, on the other hand, focuses on assigning a single label to each pixel in an image based on the category of the object it belongs to. In simpler terms, it aims to classify every pixel into predefined categories or classes, such as person, car, tree, etc. This results in a pixel-wise understanding of the image, providing valuable insights into its contents without distinguishing between different instances of the same object class.
Semantic segmentation represents a foundational task in computer vision, aiming to comprehend the visual content of an image at a pixel level. Unlike instance segmentation, which discerns between individual object instances, semantic segmentation focuses on classifying each pixel into predefined semantic categories, providing a comprehensive understanding of the scene's composition and semantics.
To perform instance segmentation, algorithms such as Mask R-CNN utilize a combination of region proposal networks (RPNs) and fully convolutional networks (FCNs) to detect objects and generate pixel-level masks for each instance within the image. This involves first identifying object bounding boxes and then refining them to produce precise segmentation masks.

Key Characteristics
a. Pixel-wise Labeling
Semantic segmentation assigns a semantic label to each pixel in an image, effectively partitioning the image into distinct regions corresponding to different object categories or classes. This pixel-wise labeling enables algorithms to capture detailed semantic information about the scene, facilitating higher-level analysis and decision-making.
b. Contextual Understanding
By considering the spatial context of pixels within an image, semantic segmentation algorithms capture rich contextual information, enhancing the overall understanding of scene semantics. This contextual understanding enables algorithms to infer relationships between objects and their surroundings, contributing to more robust and accurate segmentation results.
c. Scene Parsing and Understanding
Semantic segmentation facilitates scene parsing by segmenting the image into semantically meaningful regions, each corresponding to a specific object class or category. This scene understanding is invaluable for various applications, including image understanding, scene recognition, and visual reasoning, where a detailed understanding of scene semantics is essential.
d. Handling Class Ambiguity
Semantic segmentation algorithms exhibit robustness in handling class ambiguity, effectively distinguishing between visually similar object categories based on contextual cues and features. By leveraging contextual information and global image context, these algorithms mitigate the challenges posed by class ambiguity, ensuring accurate and reliable segmentation results across diverse scenes.
e. Applications Beyond Object Detection
While semantic segmentation is often employed as a precursor to higher-level tasks like object detection and recognition, its applications extend beyond object-level analysis. Semantic segmentation finds utility in tasks such as image editing, content-aware resizing, and image synthesis, where detailed semantic understanding of the scene is paramount.
f. Computational Efficiency
Advancements in semantic segmentation algorithms have led to improvements in computational efficiency, enabling real-time or near-real-time performance on resource-constrained devices. Techniques like dilated convolutions and efficient network architectures optimize memory and computation requirements, making semantic segmentation viable for deployment in embedded systems and mobile applications.
g. Transfer Learning and Generalization
Semantic segmentation algorithms benefit from transfer learning techniques, where models pre-trained on large-scale datasets can be fine-tuned on domain-specific or smaller datasets to adapt to specific tasks or environments. This transfer learning capability enhances the generalization and robustness of semantic segmentation models, allowing them to perform effectively across diverse datasets and scenarios.
What is Instance Segmentation?
Instance segmentation is a sophisticated computer vision task that involves identifying and delineating individual objects within an image. Unlike semantic segmentation, which assigns a single label to each pixel in an image, instance segmentation goes a step further by distinguishing between different instances of objects belonging to the same class. This means that in an image containing multiple instances of the same object class, instance segmentation algorithms are capable of not only recognizing each instance but also segmenting them separately.
Unlike its counterparts, instance segmentation not only identifies object categories but also discerns between individual instances of the same category within an image. This level of granularity allows for a more precise analysis of scenes, enabling applications to distinguish between multiple objects of the same class, even if they overlap or occlude each other.

Key Characteristics:
a. Precise Object Localization
Instance segmentation algorithms excel in accurately localizing object boundaries, providing pixel-level masks for each instance within the image. This precise localization is essential for tasks requiring detailed object delineation, such as counting objects in a crowded scene or measuring the spatial extent of individual entities.
b. Handling Object Occlusion
In real-world scenarios, objects often occlude or partially overlap with each other, posing challenges for segmentation algorithms. Instance segmentation techniques address this by not only detecting occluded objects but also segmenting them separately, preserving the integrity of each instance even in complex scenes.
c. Semantic Understanding with Instance-level Detail
While semantic segmentation offers a holistic understanding of scene semantics by assigning a single label to each pixel, instance segmentation enhances this understanding by providing instance-level detail. This means that instance segmentation not only identifies a pixel as belonging to a particular class but also associates it with a specific object instance, offering richer insights into the scene composition.
d. Handling Object Size Disparities
Instance segmentation algorithms are robust in handling objects of varying sizes within an image. Whether it's detecting tiny objects like traffic signs or large objects like vehicles, these algorithms are capable of accurately segmenting objects of different scales, contributing to their versatility across diverse applications.
e. Seamless Integration with Object Detection
Instance segmentation often integrates seamlessly with object detection frameworks, combining the capabilities of both tasks to achieve comprehensive scene understanding. By first detecting object bounding boxes and then refining them to generate instance-level masks, these integrated approaches offer a unified solution for object localization and segmentation tasks.
f. Scalability and Efficiency
Advancements in instance segmentation algorithms have led to improvements in scalability and efficiency, making them viable for real-time applications and large-scale datasets. Techniques like Mask R-CNN leverage parallel processing and optimized architectures to achieve high segmentation accuracy without compromising on speed, paving the way for deployment in resource-constrained environments.
g. Robustness to Class Imbalance
Instance segmentation algorithms exhibit robustness to class imbalance, effectively handling scenarios where certain object classes are more prevalent than others. By employing strategies like instance-aware sampling during training, these algorithms mitigate the impact of class imbalance and ensure balanced performance across different object categories.
Difference between semantic and instance segmentation
The primary difference between instance segmentation and semantic segmentation lies in their level of granularity and the information they provide. Instance segmentation offers a more detailed analysis by not only identifying object categories but also segmenting individual instances within each category. On the other hand, semantic segmentation provides a broader understanding of the scene by classifying pixels into predefined categories without distinguishing between different instances of the same class.
Understanding the differences between these segmentation techniques is crucial for determining their suitability for specific tasks and scenarios.
a. Granularity of Analysis:
- Instance Segmentation: Offers a finer level of granularity by not only identifying object categories but also distinguishing between individual instances of the same category within an image. This allows for precise delineation and segmentation of each object instance, even in cases of overlap or occlusion.
- Semantic Segmentation: Provides a holistic understanding of scene semantics by classifying each pixel into predefined semantic categories without distinguishing between different instances of the same category. While it offers a comprehensive view of the scene's composition, it does not provide instance-level detail.
b. Output Representation:
- Instance Segmentation: Outputs pixel-level masks for each individual object instance within the image, allowing for precise localization and segmentation of objects. This pixel-wise representation enables algorithms to differentiate between multiple instances of the same object class.
- Semantic Segmentation: Outputs a pixel-wise labeling of the image, where each pixel is assigned a semantic label corresponding to a predefined object category or class. The output is a segmentation map that partitions the image into regions based on semantic similarity.
c. Handling of Object Occlusion:
- Instance Segmentation: Capable of handling object occlusion by detecting and segmenting each occluded object instance separately. This ensures that even partially occluded objects are accurately segmented, preserving the integrity of each instance.
- Semantic Segmentation: Does not explicitly address object occlusion, as it assigns a single semantic label to each pixel without differentiating between occluded and non-occluded regions. Consequently, occluded objects may be inaccurately segmented or merged with adjacent objects.
d. Computational Complexity:
- Instance Segmentation: Typically involves more computationally intensive processes compared to semantic segmentation, as it requires the detection and segmentation of individual object instances within the image. This increased complexity may result in higher computational resource requirements and longer processing times.
- Semantic Segmentation: Generally involves less computational complexity compared to instance segmentation, as it focuses on pixel-wise classification without the need for instance-level segmentation. This makes semantic segmentation more suitable for real-time applications or resource-constrained environments.
How It's Done
Instance segmentation and semantic segmentation are typically accomplished using deep learning techniques, particularly convolutional neural networks (CNNs). These networks are trained on large datasets containing annotated images to learn the features necessary for accurate segmentation.
In instance segmentation, algorithms such as Mask R-CNN utilize a combination of region proposal networks (RPNs) and fully convolutional networks (FCNs) to detect objects and generate pixel-level masks for each instance within the image. This involves first identifying object bounding boxes and then refining them to produce precise segmentation masks.
Semantic segmentation, on the other hand, employs architectures like Fully Convolutional Networks (FCNs) or U-Net, which directly output pixel-wise class predictions for the entire image. These networks utilize convolutional layers to capture spatial dependencies and generate dense predictions across the image.
Use cases for Instance Segmentation
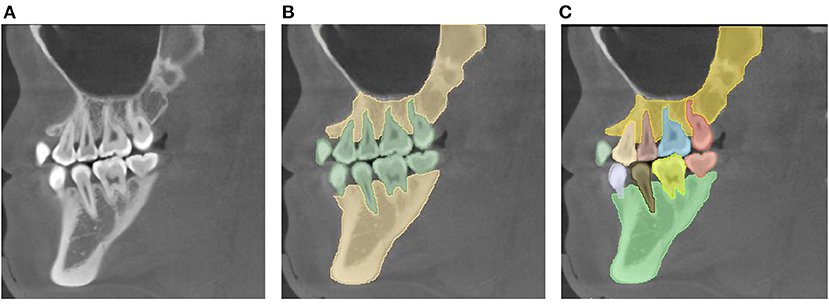
a. Autonomous Driving:
In autonomous driving systems, instance segmentation plays a crucial role in detecting and segmenting various objects on the road, such as vehicles, pedestrians, cyclists, and traffic signs. This granular understanding of the environment enables vehicles to make informed decisions and navigate safely.
b. Medical Imaging:
In medical imaging, instance segmentation is employed for tasks like tumor detection and organ segmentation. By accurately delineating individual structures within medical scans, doctors can make more precise diagnoses and plan treatments accordingly.
Use cases for Semantic Segmentation
Scene Understanding
Semantic segmentation is widely used for scene understanding in applications like image segmentation, where the goal is to partition an image into semantically meaningful regions. This is valuable in fields such as remote sensing, where satellite images are analyzed to monitor land use and environmental changes.
Augmented Reality
Semantic segmentation is also vital in augmented reality (AR) applications, where it helps in segmenting the real-world scene and overlaying virtual objects seamlessly. By understanding the semantic context of the environment, AR systems can enhance user experiences and interaction.
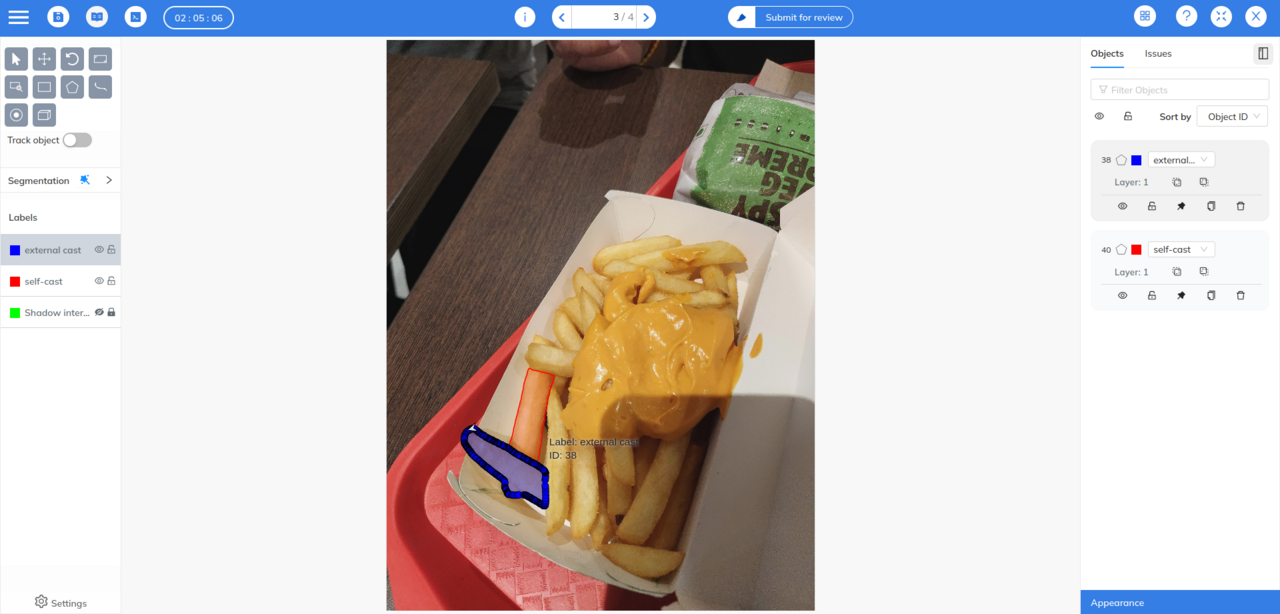
While both these segmentation techniques offer significant advantages, annotating datasets for them can be a complex, time consuming task. A good annotation tool built to handle these use-cases can be extremely useful and can be the difference between a successful and an unsuccessful AI project. The Mindkosh annotation tool is built to handle both Semantic and Instance segmentation with features like multi-layer masking, quick preview, easy exports and our automatic segmentation tool called Magic Segment. You can learn more about them here.
In conclusion, instance segmentation and semantic segmentation are both indispensable tools in the field of computer vision, each serving distinct purposes and offering unique insights into visual data. While instance segmentation excels in delineating individual objects within an image, semantic segmentation provides a broader understanding of the scene by classifying pixels into semantic categories. By leveraging deep learning techniques, these segmentation methods continue to advance, unlocking new possibilities across various domains, from autonomous driving to medical imaging and beyond.



