
For decades, AI systems learned to see the world from a distance — surveillance cameras mounted on ceilings, dashcams fixed to windshields, sensors bolted to stationary frames. The world was observed, catalogued, and modeled from the outside. That worked well enough for a generation of AI systems designed to watch the world.
But a new generation of AI is being built to live in it.
Robots that cook alongside you in the kitchen. AR glasses that understand what your hands are doing in real time. Humanoid assistants that navigate homes, warehouses, and hospital corridors. For all of these, a radically different kind of data is needed — data captured not from the outside looking in, but from the inside looking out. That's egocentric data, and it's quickly becoming one of the most critical inputs for training the next wave of physical AI.
Here's the catch: collecting this data is actually the easy part. The bottleneck — the part that separates AI systems that work beautifully from AI systems that fail in the real world — is annotation. Labeling egocentric data is genuinely hard, and most teams underestimate just how hard until they're deep in the weeds.
This blog unpacks what egocentric data is, why it matters so deeply for physical AI and robotics, what makes it so difficult to annotate well, and how purpose-built tools like Mindkosh are changing the game for teams building the intelligent systems of tomorrow.
What exactly Is Egocentric Data?
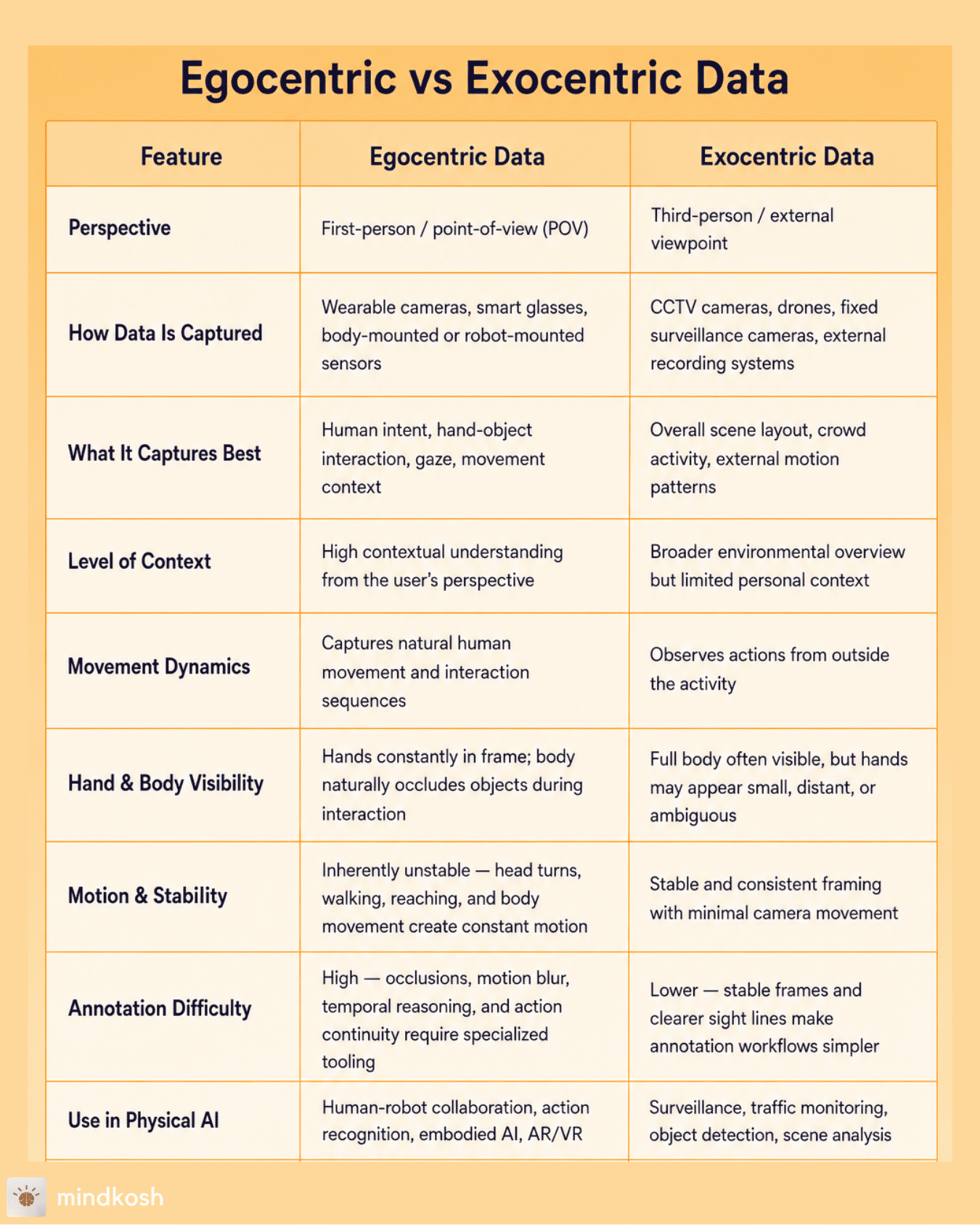
Egocentric data — sometimes called egocentric vision or first-person AI data — refers to any sensory data captured from the perspective of an agent moving through the world. Instead of a fixed, third-person viewpoint, the camera (or sensor) is attached to, or embedded within, the agent itself.
Think of it this way: exocentric data is what a security camera sees. Egocentric data is what you see.
This distinction sounds simple, but it has profound implications. In an egocentric feed, your hands are almost always in the frame. Your body occludes objects constantly. The horizon tilts when you lean. The image shakes when you walk. Objects appear, disappear, and reappear as your gaze shifts. Nothing is static. Everything is dynamic, contextual, and deeply personal.
The most common sources of egocentric data include:
Wearable cameras — Devices like GoPros, Meta's Project Aria research glasses, or purpose-built head-mounted rigs capture first-person video as humans go about daily tasks. These are invaluable for building datasets that teach AI systems how people really interact with their environments.
Robot-mounted cameras — Cameras fixed to a robot's "head" or end-effectors capture what the robot sees as it navigates and manipulates objects. The perspective shifts constantly as the robot moves, making this data qualitatively different from fixed-camera datasets.
Multimodal sensor streams — Modern egocentric rigs often combine RGB video with depth sensors (like LiDAR or structured light), IMUs (inertial measurement units), gaze trackers, and microphones. The resulting dataset is rich but complex — multiple streams that need to be synchronized and jointly annotated.
Extended Reality (XR) devices — AR and VR headsets like the Apple Vision Pro, Meta Quest, and Microsoft HoloLens—continuously capture first-person spatial data about the user's physical environment.
The contrast with exocentric, or third-person, data becomes starkest when you think about what an AI system actually needs to understand. A robot watching a video of someone picking up a coffee cup learns very little about how to do that task itself. But a robot trained on first-person footage of the act — the hand reaching, fingers wrapping, wrist adjusting for weight — gets something fundamentally more useful.
Egocentric data and Physical AI
Physical AI — AI that operates in and interacts with the physical world — is one of the most exciting and most demanding frontiers in technology today. Robotics companies, warehouse automation providers, surgical robotics firms, and consumer robotics startups are all racing to build systems that can handle real-world variability. The common denominator? They all need training data that reflects how physical tasks actually happen, from the perspective of the agent doing them.
Here's why egocentric data is non-negotiable for this class of AI:
Human-object interaction. The most important moments in physical AI—picking, placing, assembling, sorting, and handing off—are defined by close-range, first-person contact between hands and objects. Egocentric data is the only type that captures these interactions in a way that's directly transferable to robot learning.
Action prediction. For a robot to be genuinely helpful, it can't just react—it needs to anticipate. Egocentric data provides the temporal context for this: what did the person (or robot) look at just before grabbing something? What's the typical sequence of steps in this task? Training on first-person action sequences enables action prediction in a way that third-person data simply cannot.
Spatial reasoning. Embodied AI needs to understand space from a first-person perspective—how far away an object is, whether there's room to reach, and how to navigate without bumping into things. Egocentric data, especially when paired with depth sensors, gives AI systems the geometric grounding they need.
Context awareness. What task is being performed? What's the environment? Who else is present? Egocentric data is inherently context-rich because it captures the full situational context from the agent's perspective, not just the isolated action.
Major AI research initiatives have recognized this. Meta's Ego4D project — one of the largest egocentric video datasets ever assembled — brought together 74 worldwide locations across 9 countries to collect 3,670 hours of daily-life egocentric video. The follow-up Ego-Exo4D dataset goes even further, pairing egocentric footage with simultaneous exocentric views to enable richer training. These projects signal just how central first-person data has become to the future of embodied AI.
For businesses investing in physical AI—whether you're building humanoid robots, warehouse automation systems, surgical assistants, or AR tools for field workers—egocentric data isn't a nice-to-have. It's a foundational requirement. At the same time, it's also worth addressing synthetic data. Collecting real-world egocentric footage at the speed and scale physical AI demands is genuinely difficult—you can't easily stage thousands of edge-case scenarios in the real world.
That's why companies are increasingly turning to simulation engines like NVIDIA Isaac Sim and DeepMind's MuJoCo to generate training data programmatically, randomizing lighting, object positions, and physics to build edge-case-rich datasets at scale. The appeal is real. But so is the sim-to-real gap — the well-documented performance drop that happens when a model trained in simulation meets the messiness of the real world. In practice, the most serious physical AI pipelines use synthetic data to augment real-world egocentric data, not replace it—both matter. And as you'll see, both still need to be annotated well.
In all likelihood, the data pipelines powering the next generation of physical AI will be a blend of both — synthetic data for scale and edge-case coverage, real-world egocentric footage for the nuance and authenticity that simulation can't replicate."
The image below shows an egocentric video annotation workflow showing hand-object interaction labeling for Physical AI and robotics training systems. Source: Ego4D Dataset Annotation Guidelines (Meta AI Research)

The annotation problem: Why Egocentric data is so hard to label
ML models need labeled data in order to learn from them. And here's where many physical AI projects run into trouble. They've done the hard work of collecting first-person data. They have terabytes of wearable camera footage or robot-mounted video. And then they discover that annotating it is a completely different beast from labeling standard image datasets.
Several factors make egocentric data annotation genuinely difficult:
Shaky, unstable footage. First-person video is inherently unsteady. Every head turn, step, or arm movement creates motion blur, perspective shifts, and frame discontinuities that make consistent labeling very hard. An annotator trying to track an object across frames has to mentally compensate for constant camera movement.
Pervasive occlusions. In first-person footage, objects are constantly being occluded — by hands, by the body, by other objects. A bottle partially hidden behind a hand is still a bottle, and a well-trained AI needs to know that. But labeling objects through occlusions requires annotators to reason carefully about what's visible and what can be inferred.
Temporal continuity. Action recognition annotation requires understanding sequences, not individual frames. An annotator can't just label "hand picks up mug" on a single frame — they need to identify the start frame of the reaching motion, track through the grasp, and mark the end of the action. This temporal reasoning demands a fundamentally different annotation workflow from static image labeling.
Ambiguous actions. Human behavior is often ambiguous. Is the person adjusting an object's position or beginning to pick it up? Are they looking at something intentionally or just glancing? In egocentric video, where context is everything, these ambiguities multiply. Good annotation requires annotators who understand the task context, not just the visual content.
Multi-sensor synchronization. When egocentric data includes depth, IMU, gaze, and audio streams alongside video, annotators need to work across synchronized streams simultaneously. A label on the RGB frame needs to align precisely with the corresponding depth frame and IMU timestamp. Getting this right requires tooling built specifically for multi-modal pipelines.
Scale. Physical AI models need a lot of data. Ego4D alone required coordinated annotation of thousands of hours of footage. Without efficient, quality-controlled annotation workflows, the data pipeline becomes the bottleneck for the entire AI development project.
These challenges are very real in practice and can slow down physical AI teams and push timelines from months to years.
Keypoint annotation: The heartbeat of Egocentric AI
Of all the annotation techniques relevant to egocentric data, keypoint annotation deserves special attention. It's arguably the most commercially important for teams building physical AI systems, and it's where annotation quality has the most direct impact on downstream model performance.
Keypoint annotation involves labeling specific anatomical landmarks — joints, fingertips, knuckles — on a body or body part across video frames. For egocentric AI, hand keypoint annotation is paramount.
Think about what a robot needs to understand to manipulate objects skillfully: the position of every fingertip, the bend at every knuckle, the angle of the wrist, the spread of the palm. These aren't just descriptive labels — they're the raw signals from which hand pose estimation, gesture recognition, and intent modeling are all derived.
When an AI system learns from properly annotated hand keypoints, it can:
- Track fine-grained hand movements with enough resolution to distinguish a pinch grip from a power grip, or a pointing gesture from a scrolling motion.
- Model finger positioning through complex manipulation tasks — threading a needle, tying a knot, assembling a component.
- Understand object interaction at a mechanical level — how the fingers conform to the shape of an object, where force is likely being applied.
- Infer human intent. Before a hand closes around an object, the approach trajectory, finger pre-shaping, and gaze direction together tell a story about what's about to happen. Models trained on rich keypoint data can learn to read that story.
This is why datasets like Ego-Exo4D invest so heavily in skeletal and keypoint annotation. And it's why, for any organization building systems that need to understand human hands—robotic manipulation, AR interaction, gesture-controlled interfaces, prosthetics, and surgical robotics—keypoint annotation isn't optional infrastructure. It's the thing that makes the model work.
Getting keypoint annotation right in egocentric video is technically demanding. Fingers occlude each other constantly. Hands move fast. In video, every keypoint needs to be tracked with frame-level consistency, not just labeled in isolation. The tooling and workflow matter enormously.

The full annotation stack for Egocentric data
Keypoints are critical, but they're part of a broader annotation ecosystem that egocentric AI models require. Here's a practical breakdown of what a complete egocentric data annotation pipeline typically needs to cover:
Object Detection and Tracking
Objects in egocentric video need to be identified, classified, and tracked across frames as the camera moves. This is more demanding than static object detection because the apparent position, scale, and orientation of objects shifts constantly with camera motion.
Action Recognition Annotation
AI models trained on egocentric data need to understand what actions are being performed, when they start, and when they end. This requires temporal segmentation — identifying the precise boundaries of actions across video sequences — along with hierarchical labeling (the action "make coffee" is composed of sub-actions "open cupboard," "take mug," "pour water," and so on).
Skeleton and Pose Annotation
Beyond hand keypoints, full-body pose annotation — labeling the positions of shoulders, elbows, knees, hips, and other joints — is important for tasks where whole-body movement matters, such as in humanoid robotics or athletic performance analysis.
Intent and Gaze Labeling
This is the frontier of egocentric annotation. Gaze tracking tells you where an agent was looking; intent labeling assigns a purpose or goal to a sequence of actions. Together, they enable AI systems that don't just observe behavior but understand the reason behind it — a capability critical for proactive robot assistance.
3D Keypoint annotation
Another frontier in egocentric data annotation is labeling 2D videos with 3D co-ordinates that include x,y, as well as z cordinates. Depth estimation is a crucial aspect of understanding what is happening in the environment. However there are currently no annotation tools available that allow labeling and editing 3D co-ordinates on 2-D images. Mindkosh is building a new Proof-of-concept 3D annotation tool for egoecntric data that is expected to go live by late May 2026. If you are interested in seeing it in action, let us know.
Each of these annotation types requires different tools, different annotator expertise, and different quality assurance processes. That's a significant operational challenge for AI teams — and exactly the reason why choosing the right annotation platform matters so much.

Quality is not optional: Why annotation errors compound
There's a tempting shortcut that many AI teams take: prioritize annotation speed over annotation quality to hit dataset size targets faster. The logic seems reasonable — more data means better models, right?
In practice, for egocentric data, this thinking backfires badly.
The reason is that annotation errors in first-person video don't stay isolated. A mislabeled keypoint in frame 100 of a video sequence cascades forward: the model learns a subtly wrong hand pose, which leads to subtly wrong predictions about grip behavior, which leads to manipulation failures in real-world deployment. Errors compound through temporal sequences in ways they don't in static image datasets.
This is why quality assurance workflows are not optional for egocentric annotation pipelines. Specifically, teams need:
Multi-stage review. Annotations should pass through at least two stages of review — a primary annotator's pass followed by a senior reviewer's check. For especially complex annotation types like intent labeling or multi-keypoint hand tracking, consensus annotation (where multiple annotators independently label the same data and disagreements are adjudicated) provides the highest quality floor.
Human-in-the-loop validation. Automated quality checks — detecting keypoint positions that fall outside plausible anatomical ranges, flagging action label boundaries that seem inconsistent — can catch many errors at scale. But edge cases require human judgment, and building a workflow where human reviewers are systematically incorporated is essential.
Edge case coverage. Physical AI deployments fail at edge cases. The robot that works 98% of the time and catastrophically fails the other 2% is not a trustworthy robot. Annotation pipelines need to deliberately seek out and carefully annotate edge cases — unusual hand positions, occluded objects, atypical lighting, and ambiguous actions—not just the common cases.
This applies equally to teams leaning on synthetic data. Auto-generated labels from simulation engines are appealing—the simulator knows exactly where every object is, so ground truth annotations come built in. But they're not clean by default. Simulation artifacts, imprecise physics, and edge-case boundary errors mean synthetic labels regularly need human review before they're fit for training.
More importantly, there are things a simulator cannot label at all — the intent behind an action, the contextual meaning of a gesture, the nuance that separates one behavior from another. Those gaps still require human annotators, and they require them to work carefully. Whether your pipeline runs on real-world egocentric footage, synthetic data, or a combination of both, annotation quality at the top of the stack remains the variable that determines real-world performance. Annotation quality is, ultimately, a proxy for real-world reliability. The two are directly linked.
How Mindkosh supports Egocentric data annotation
Mindkosh offer data annotation solutions specifically designed for Physical AI. The Mindkosh annotation platform was built for exactly the kind of complex, high-stakes annotation work that physical AI development demands. Combined with an experienced workforce that knows how to handle the challenges associated with labeling egocentric data, Mindkosh
Here's what that looks like in practice:
Multi-frame and video annotation workflows. Mindkosh supports seamless annotation across video sequences, with frame interpolation and tracking capabilities that dramatically reduce the labor required to annotate objects and keypoints through long video clips. Annotators can label a keypoint position in one frame and propagate it forward, then review and correct rather than starting from scratch on every frame.
Full keypoint and skeleton annotation support. For teams doing hand keypoint annotation, pose estimation annotation, or full-body skeleton labeling, Mindkosh provides configurable keypoint schemas — define the joints and their relationships, and the platform enforces anatomical constraints and consistency across frames. This reduces annotation errors at the point of entry, not just in post-review.
Multi-sensor pipeline support. Egocentric data rarely comes as just RGB video. Mindkosh supports synchronized annotation across multiple sensor modalities — video, depth, and LiDAR point clouds — in a unified interface. Annotators work across streams simultaneously rather than having to reconcile separately labeled datasets.
QA workflows. The primary focus for our labeling teams remains Quality assurance. Every data asset is subjected to a 2-level annotation review - by separate teams. We can also setup reliable Quality measuring metrics like honeypot to pin accurate quality metrics to the labeled data. The Mindkosh platform allows users to analyse performance and QA metrics in real time, giving teams visibility into data quality across the entire annotation operation.
Scalable team management. For organizations annotating at the scale that serious physical AI projects require — thousands of hours of footage, multiple annotation types, tight timelines — Mindkosh provides the project management infrastructure to coordinate large annotation teams without quality degradation at scale.
For businesses that are building physical AI systems and know they need a data partner who understands the specific demands of first-person, embodied AI data, Mindkosh offers both the tooling and the expertise to get it right.
The road ahead: Where egocentric AI is going
The trajectory of egocentric AI is clear, and it's moving fast.
Humanoid robotics is transitioning from research novelty to commercial reality. Companies like Figure, Boston Dynamics, and Agility Robotics are deploying bipedal robots in warehouses and industrial settings. Each of these systems needs training data that captures skilled human manipulation from a first-person perspective — and the demand for annotated egocentric data will scale accordingly.
AR glasses are about to have their moment. Devices from Meta, Apple, and Google are reaching mainstream viability, and the AI systems embedded in them — systems that understand what your hands are doing, what objects you're looking at, what task you're trying to accomplish — are all trained on egocentric data. The consumer scale of this market will drive demand for first-person data annotation that dwarfs current research datasets.
Robotic copilots for professionals — surgeons, technicians, field workers — are an emerging category where egocentric AI needs to understand expert-level human performance. Annotating these datasets requires domain knowledge as well as annotation skill, raising the bar further for annotation providers.
Human-aware AI more broadly — systems that can model human intent, predict human needs, and coordinate with humans in shared physical spaces — depends fundamentally on first-person data. The field of egocentric AI is, in a real sense, the field of human-aware AI.
Meta's continued investment in Ego4D and Project Aria, the explosion of foundation models for embodied AI, and the growing chorus of physical AI startups raising large rounds are all pointing in the same direction: egocentric data is becoming critical infrastructure for the AI systems that will define the next decade.
The annotation advantage
Here's the bottom line for businesses building physical AI: egocentric data is the foundation your models are built on, and annotation quality is what determines whether that foundation holds.
The companies that figure out their egocentric data pipelines early — that invest in high-quality annotation infrastructure now rather than retrofitting it later — will build AI systems that are more reliable, more capable, and more trusted. The companies that cut corners on annotation will spend years chasing model failures that trace back to labeling errors they can no longer find.
The technology frontier is moving at extraordinary speed. But at every step along the way, the quality of annotated training data remains the variable that separates systems that work in the lab from systems that work in the world.
If you're building physical AI and ready to invest in the data foundation it deserves, Mindkosh is built for exactly this challenge. Explore the platform, connect with the team, and let's build smarter robots together.



