Optical Character Recognition (OCR) is a powerful technology that converts various types of documents, such as scanned paper documents, PDFs, or images captured by digital cameras, into editable and searchable data. With the growing influence of Natural Language Processing (NLP), OCR's role has expanded significantly. This blog explores OCR Image annotation for NLP, providing insights into its importance, techniques, tools, and best practices.
What is NLP?
Natural Language Processing (NLP) is a branch of Artificial Intelligence that helps computers understand, interpret, and manipulate human language. It is used in applications like sentiment analysis, machine translation, and chat-bots.
Not so long ago, different NLP tasks were performed through the use of specialized techniques. With the advent of LLMs (large language models), most of the NLP tasks like NER (Named Entity Recognition), sentiment analysis and summarizing, can be performed by a single LLM. These LLMs are versatile enough that they can work on different types of text, different lengths of text as well as on texts in different languages. All while providing a natural language interface. This has revolutionized the industry and finally brought AI to the masses.
Commonly used NLP tasks
- Text Classification
Categorizing text into predefined classes or categories. For e.g. categorizing a piece of news article into sports, politics, entertainment etc. - Entity Recognition:
Tagging individual words in a sentence according to contextual usage, such as nouns, verbs, adjectives, etc. - Sentiment Analysis
Determining the sentiment expressed in the text. This could be helpful in text moderation, determining the outcome of a customer call etc. - Intent Detection
Identifying the intent behind the text. This is a crucial step in speech recognition softwares like Siri or Alexa. Once speech has been transformed into text, an intent detection system tries to understand what the user wants to accomplish. - Semantic Analysis:
Understanding the meaning and context of the text, with a variety of context, implications etc.
What is OCR?

Optical Character Recognition (OCR) is a technology used to convert different types of documents, such as scanned paper documents, PDFs, or images taken by a digital camera, into editable and searchable data. It plays a crucial role in digitizing printed and handwritten text.
Here are several key areas highlighting the importance of OCR in NLP:
Data Digitization
- Document Conversion: OCR technology enables the conversion of printed and handwritten text into digital formats. This digitization process is crucial for making large volumes of text data accessible and usable for NLP applications.
- Searchability: Once text is digitized, it becomes instantly searchable. This is invaluable for quickly retrieving information from extensive document archives.
Document Processing
- Efficient Data Retrieval: OCR facilitates the extraction of relevant information from documents such as invoices, forms, and legal documents. NLP techniques can then process this data to extract entities, classify text, and analyze sentiment.
- Workflow Automation: By automating the data extraction process, OCR significantly reduces the manual effort required to process documents, leading to improved efficiency and accuracy in tasks like data entry and validation.
Content Analysis
- Text Classification: OCR enables the categorization of text data into predefined classes. For instance, documents can be classified into categories such as legal, medical, or financial based on their content.
- Sentiment and Intent Analysis: By digitizing customer feedback forms, social media posts, and other text sources, OCR allows NLP models to perform sentiment and intent analysis, providing insights into customer opinions and behaviors.
Improved Accessibility
- For Visually Impaired Users: OCR technology helps convert printed materials into digital formats that can be read aloud using screen readers, making information accessible to visually impaired individuals.
- Language Translation: OCR combined with NLP translation models can convert text from one language to another, facilitating the accessibility of information across different linguistic groups.
Enabling Advanced NLP Applications
- Machine Learning and Deep Learning: OCR-processed data is crucial for training machine learning and deep learning models in NLP. High-quality annotated data leads to better model performance in tasks such as named entity recognition, text summarization, and language modeling.
- Real-Time Applications: OCR enables real-time text extraction and analysis, which is vital for applications like live transcription, automated customer support, and instant document verification.
Integration with Other Technologies
- IoT and Smart Devices: OCR is integral in IoT applications, such as smart scanners and cameras, which capture and digitize text data for further processing by NLP models.
- Augmented Reality (AR): In AR applications, OCR helps overlay digital information on real-world objects by recognizing and interpreting text within the visual field.
Enhancing Business Intelligence
- Data Mining: OCR facilitates the extraction of valuable insights from large text corpora, enabling businesses to make data-driven decisions.
- Trend Analysis: By processing and analyzing text data from various sources, businesses can identify trends and patterns that inform strategic planning and operational improvements.
Annotating data for OCR
Data is the secret sauce that makes Machine Learning systems perform accurate detection. A key component of any data pipeline is data annotation, so the ML models can learn from it. Here are a few techniques for labeling data for OCR systems.
Manual Annotation
Manual annotation is the traditional method of labeling data. While it is still the most widely used method, it is quickly being replaced by at-least partly automated labeling. Manual annotation may sometimes be your only choice if the data is very complicated. In general, labeling data manually is expensive and time-consuming.
- Pros: High accuracy, human intuition.
- Cons: Time-consuming and expensive.
Semi-Automatic Annotation
Semi automatic labeling tools aim to utilize some form of user intervention and direction automatically detect text. This is faster than completely manual annotation, but it can sometimes get tricky to train a large labeling team to properly use the semi-automatic tools.
- Pros: Faster than manual, good accuracy.
- Cons: Still requires human intervention, can be tricky to train labeling team.
Fully Automatic Annotation
Wherever possible, this should be the go-to method for labeling. It does not require human intervention to start labeling, and works very well for most common use cases.
- Pros: Fast, scalable.
- Cons: May lack accuracy, depending on the complexity of the use case.
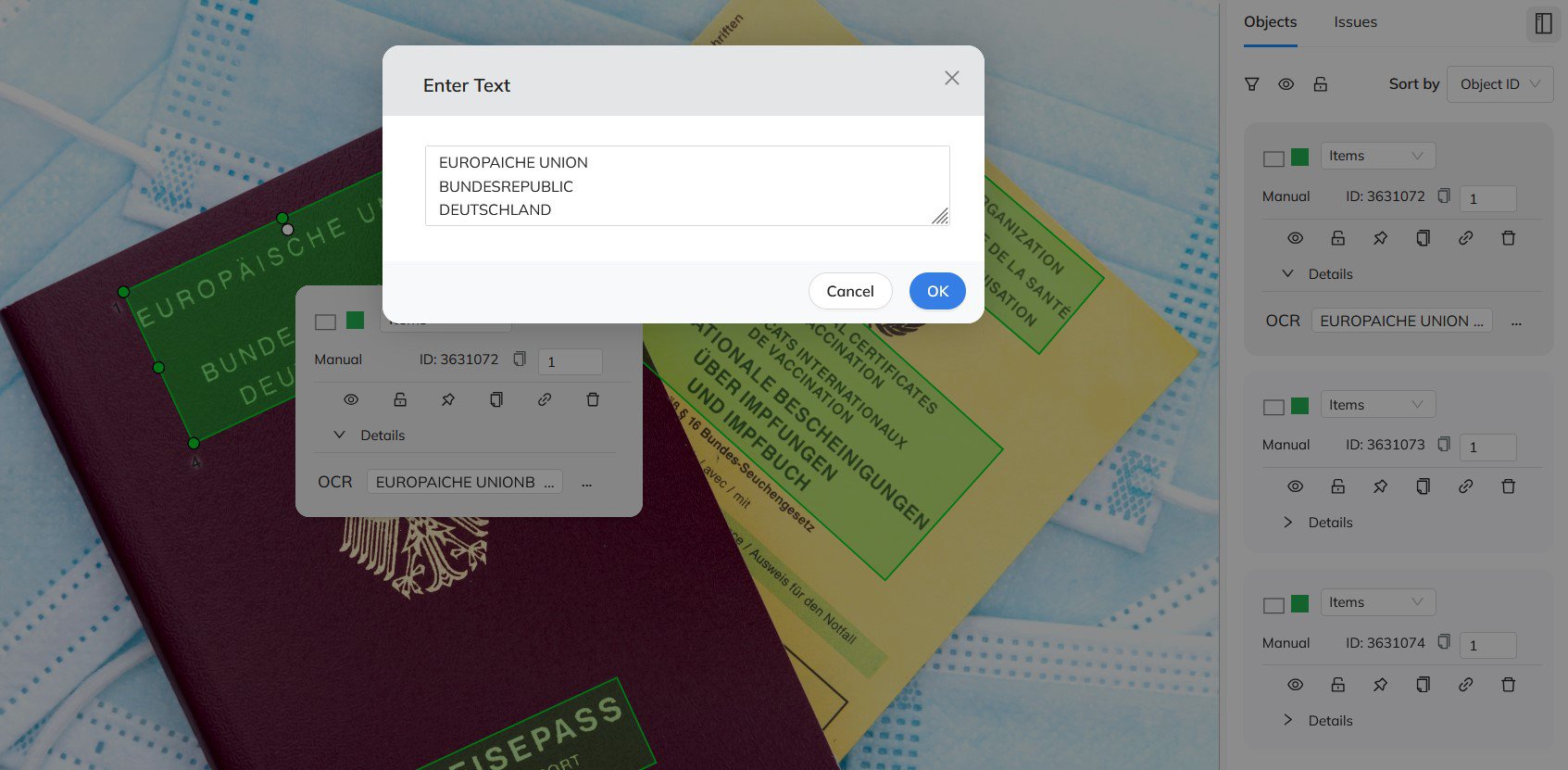
Mindkosh's OCR annotation tool offers a fully automatic annotation mode, that detects the location as well as content of all the text in your images. You can also choose to detect text by token, lines or paragraphs depending on your use-case. And the best part? It works on all major languages across the globe! You can learn more about our OCR annotation tool here.
Best Practices for OCR Annotation
Ensure High-Quality Scans
- Tip: Use high-resolution images to improve OCR accuracy.
- Recommendation: Minimum of 300 DPI for documents.
Choose the Right Tools
- Tip: Select tools that best fit your specific annotation needs.
- Recommendation: Use specialized OCR
tools for specific tasks like handwritten text recognition.
Validate and Review Annotations
- Tip: Regularly review and validate annotations to ensure accuracy.
- Recommendation: Implement a quality control process involving multiple reviewers.
Use Metadata Effectively
- Tip: Annotate text with relevant metadata to improve model training.
- Recommendation: Include attributes like language, context, and source.
Optimize Workflow
- Tip: Streamline your annotation process to save time and reduce errors.
- Recommendation: Use workflow automation tools to manage large-scale annotation projects.
Challenges with OCR

While OCR technology has revolutionized the way we handle textual data, it is not without its challenges. These challenges can impact the effectiveness of NLP applications. Below, we discuss some of the major challenges faced in OCR annotation and the solutions to mitigate these issues.
Accuracy of Text Recognition
- Handwritten Text: OCR systems often struggle with recognizing handwritten text due to the variability in handwriting styles.
- Complex Fonts and Layouts: Documents with complex fonts, decorative text, or non-standard layouts can pose significant challenges for OCR systems.
- Noise and Image Quality: Poor quality images, such as those with noise, low resolution, or distortion, can reduce the accuracy of text recognition.
Multilingual Text Recognition
- Multiple Languages and Scripts: Documents containing multiple languages or scripts can confuse OCR systems that are not trained on diverse datasets.
- Special Characters and Diacritics: Languages with special characters or diacritics (e.g., accents in French, umlauts in German) can be difficult for OCR systems to recognize accurately.
Contextual Understanding
- Lack of Context: OCR systems typically recognize text at a character or word level without understanding the broader context, leading to misinterpretations.
- Semantic Errors: Misrecognized words can lead to semantic errors that affect the subsequent NLP tasks, such as sentiment analysis or entity recognition.
Annotation Quality and Consistency
- Human Error: Manual annotation is prone to human errors, leading to inconsistencies in the annotated data.
- Annotation Guidelines: Lack of clear guidelines can result in varied annotation standards, affecting the quality of the training data.
Possible solutions
Improving Text Recognition Accuracy
- Advanced OCR Algorithms: Implementing advanced OCR algorithms, such as those based on deep learning, can improve the recognition of complex fonts and handwritten text.
- Preprocessing Techniques: Image preprocessing techniques like noise reduction, binarization, and image enhancement can improve the quality of the input for OCR systems.
- Specialized Training Data: Using large datasets with diverse handwriting samples, fonts, and layouts for training can enhance the accuracy of OCR systems.
Enhancing Multilingual Recognition
- Language Models: Incorporating language models that support multiple languages and scripts can help OCR systems handle multilingual documents more effectively.
- Character Recognition Models: Developing and training models specifically for recognizing special characters and diacritics can reduce errors in multilingual text recognition.
Contextual Understanding and Correction
- Post-OCR Correction: Implementing post-OCR correction mechanisms using NLP techniques can help correct misrecognized words based on context.
- Context-Aware Models: Developing OCR systems that incorporate context-aware models can improve the recognition and interpretation of text in context.
Ensuring Annotation Quality and Consistency
- Annotation Tools: Utilizing advanced annotation tools with built-in validation checks can reduce human errors and ensure consistency.
- Clear Guidelines: Establishing clear and detailed annotation guidelines can standardize the annotation process, improving the quality of the training data.
- Automated Annotation: Leveraging automated annotation techniques, such as using pre-trained models to pseudo-annotate data, can enhance the efficiency and consistency of the annotation process.
Future Trends
The future of OCR annotation for NLP is promising, with several trends likely to shape its development:
Enhanced AI Models
- Trend: Continued development of more sophisticated AI models for OCR, improving accuracy and capability in diverse contexts.
- Impact: Better handling of complex and low-quality documents.
Integration with NLP
- Trend: Deeper integration of OCR with NLP applications, allowing for more seamless processing of text from diverse sources.
- Impact: Enhanced ability to analyze and understand large volumes of text data.
Cloud-Based Solutions
- Trend: Increasing use of cloud-based OCR services, providing scalable and accessible solutions for businesses of all sizes.
- Impact: Reduced infrastructure costs and easier deployment of OCR technologies.
Real-Time Processing
- Trend: Development of real-time OCR processing capabilities, particularly useful for applications like live translation and instant data extraction.
- Impact: Increased efficiency and immediacy in data processing tasks.
Conclusion
OCR annotation is an essential component in the advancement of NLP, enabling the conversion of diverse text formats into machine-readable data. By understanding the various types of OCR annotation, employing effective techniques and tools, and adhering to best practices, you can significantly enhance the quality and efficiency of your NLP projects. As technology continues to evolve, staying abreast of new trends and developments will ensure that your OCR annotation processes remain cutting-edge and effective.
Incorporate these insights into your workflow, and you’ll be well on your way to leveraging the full potential of OCR and NLP in your projects.