As AI models grow more complex, the demand for high-quality labeled data increases. But one issue continues to slow down production: inconsistent annotations.
Whether you're labeling images, LiDAR point clouds, or medical scans — accuracy matters - a lot. In industries like autonomous driving or healthcare, a small mistake can not only derail your model’s performance, but also lead to safety risks.
Consider the case of this startup building autonomous delivery vehicles, for example. Despite a high annotation volume, their QA team faced two persistent bottlenecks:
- Long quality-checking cycles.
- Label inconsistencies between annotators.
Both issues directly affected model training speed and accuracy.
The problem - Poor quality annotations
When labeling is rushed or lacks proper oversight, the result is noisy and inconsistent data. This not only leads to poor model performance but also wastes valuable time and resources as teams are forced to revisit and correct mislabeled samples. These delays can significantly slow down development cycles, especially in high-stakes industries like autonomous driving or healthcare, where accuracy is critical.
Poor quality annotations create cascading failures throughout a Machine Learning pipeline. This is made even worse by the fact that ML models appear to train successfully but fail catastrophically in production.
Inconsistent labeling standards can lead to conflicting signals during training, causing models to learn incorrect correlations.
Mislabeled edge cases particularly harm model robustness, as these challenging examples are very important for teaching models how to handle real-world scenarios.
The cost of poor annotations compounds over time—models trained on flawed data require extensive retraining once issues are discovered, and the debugging process becomes exponentially more complex when annotation quality varies across different annotators or time periods. Additionally, biased or incomplete annotations can embed systematic errors into models, creating fairness issues and limiting generalization to underrepresented scenarios in the dataset.
The solution: Built in QC tools
By adopting a QA-first approach, Mindkosh helps teams catch issues early—before they become costly bottlenecks. Mindkosh’s validation-first workflows are designed to identify inconsistencies in real time, allowing teams to address errors before they reach production. Instead of reviewing every annotation manually, reviewers can now focus only on outliers or edge cases, saving time and effort.
1. What is multi-annotator validation?
In a standard QA process, annotations are reviewed manually after they’re submitted. But with multi-annotator validation, the same data is assigned to multiple annotators upfront. This allows the system to:
- Compare annotations automatically
- Measure agreement scores
- Highlight discrepancies early
Mindkosh enables this with built-in agreement metrics like majority voting and overlap scores. As soon as inconsistencies are detected, they’re flagged for review — long before they impact your models.
Example: If three annotators label a vehicle in LiDAR differently, the platform scores the overlap between their cuboids and surfaces the disagreement for resolution.
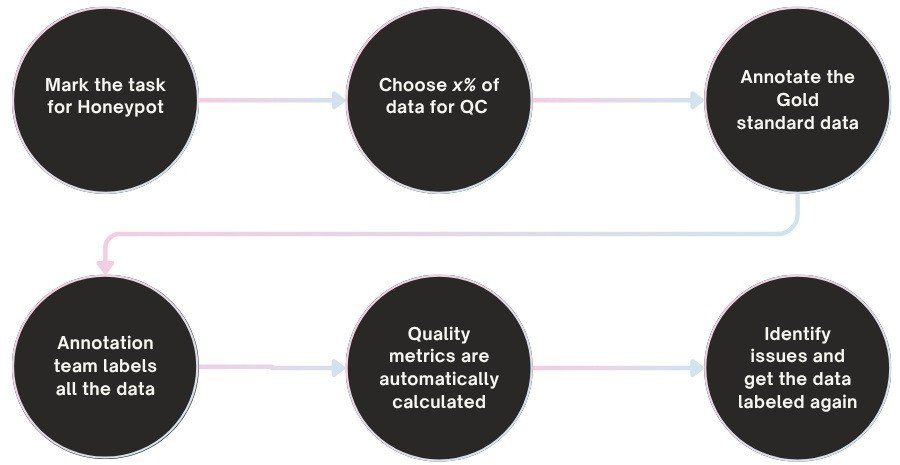
2. What are honeypot tasks?
Honeypot tasks are pre-labeled samples secretly inserted into a workflow. They are used to measure annotator accuracy in real time — without requiring additional review effort.
Mindkosh supports honeypots natively. When annotators interact with these known tasks, their performance is scored and tracked automatically. This helps:
- Identify training needs
- Catch low-performing annotators early
- Maintain consistent quality across teams
3. Reviewer interface that focuses on the edge cases
Rather than reviewing every label, reviewers on Mindkosh can focus on just the low-agreement samples or flagged issues.
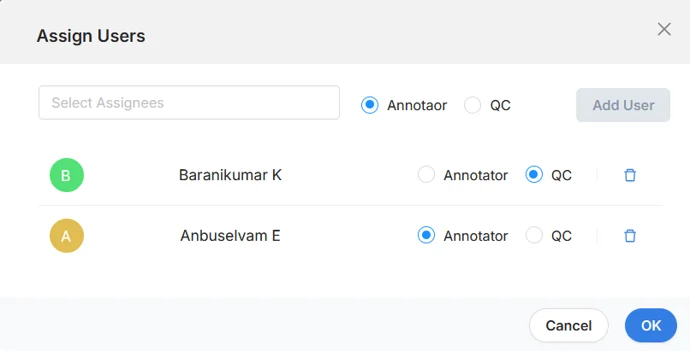
Mindkosh’s reviewer interface allows you to:
- View all annotator versions side by side
- Flag conflicts
- Approve or fix discrepancies with context
This targeted review saves time and ensures only high-trust data moves to production.
Why does QA-first annotation matter?
A reactive QA process only delays issues. A proactive one prevents them. With Mindkosh’s validation-first workflows:
- Quality issues are flagged before they reach production
- Reviewers focus on edge cases, not every sample
- Models are trained on clean, trusted data from the start
In other words: fewer errors, faster iteration, better outcomes.
Other tools that can improve accuracy further
Mindkosh is more than just a labeling platform — it’s a complete ecosystem designed to boost annotation accuracy and efficiency at every stage. Beyond validation workflows, the platform offers several integrated tools that enhance data quality and simplify large-scale project management.
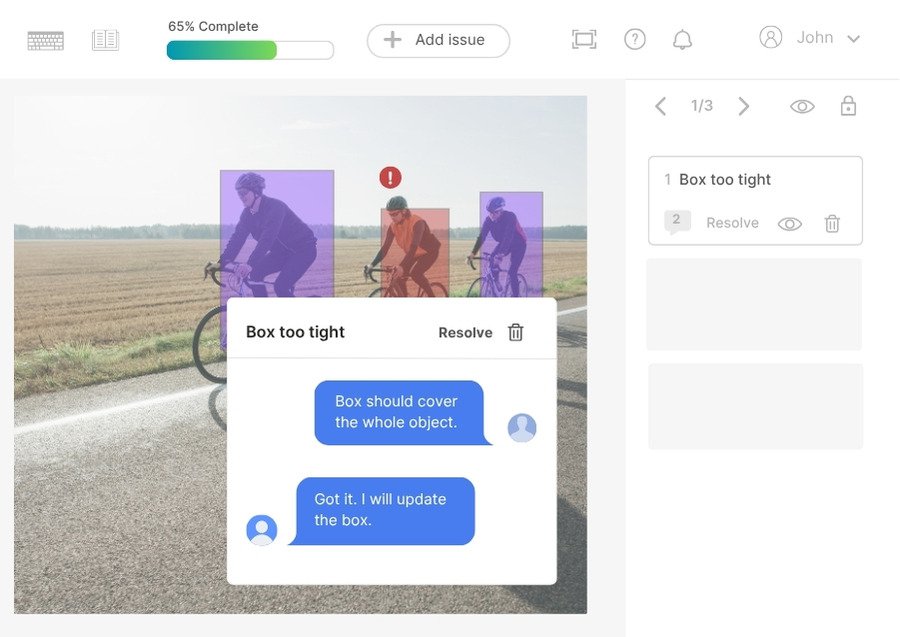
Issue tracking dashboard
Annotation can sometimes be ambiguous — maybe the image is blurry, or the object is partially occluded. With Mindkosh's built-in issue tracking system, annotators can flag such edge cases directly within the platform. This ensures that difficult samples are escalated to reviewers or project leads, instead of slipping through unnoticed. As a result, confusion is reduced, and teams can maintain consistency across large datasets.
Reviewer scoring system
Not all annotators perform equally — and that’s okay. What matters is identifying strengths and gaps early. Mindkosh’s reviewer scoring tool lets you track annotator performance over time, including metrics like accuracy, speed, and consistency. This feedback loop enables better training, smarter task assignments, and ultimately, higher-quality output.
Auto-labeling
For tasks like video or sequential image labeling, where objects appear across multiple frames, manually annotating each frame can be repetitive and time-consuming. Mindkosh supports interpolation — automatically generating labels between keyframes — as well as AI-assisted auto-labeling for repetitive structures. These tools not only accelerate the process but also reduce human fatigue, which is a leading cause of annotation errors.
Conclusion: Data quality is a workflow problem — Mindkosh fixes that
Mindkosh isn't just a labeling tool. It’s a quality assurance engine. With multi-annotator validation, honeypot testing, and seamless reviewer workflows, you’ll spend less time reviewing and more time shipping models that work.
- Less guesswork
- More agreement
- Faster delivery
Ready to streamline annotation quality? Try Mindkosh and reduce review time today.