
What is data collection and why is it important for ML?
Data is the secret sauce that makes Machine Learning models perform well. However, not all data is created equal, and the strategies you use to gather and prepare the data can make or break the performance of your ML models. In this blog, we will talk about the practical approaches to collecting high-quality data, ensuring that your Machine Learning projects are set up for success.
Data Collection process for Machine Learning
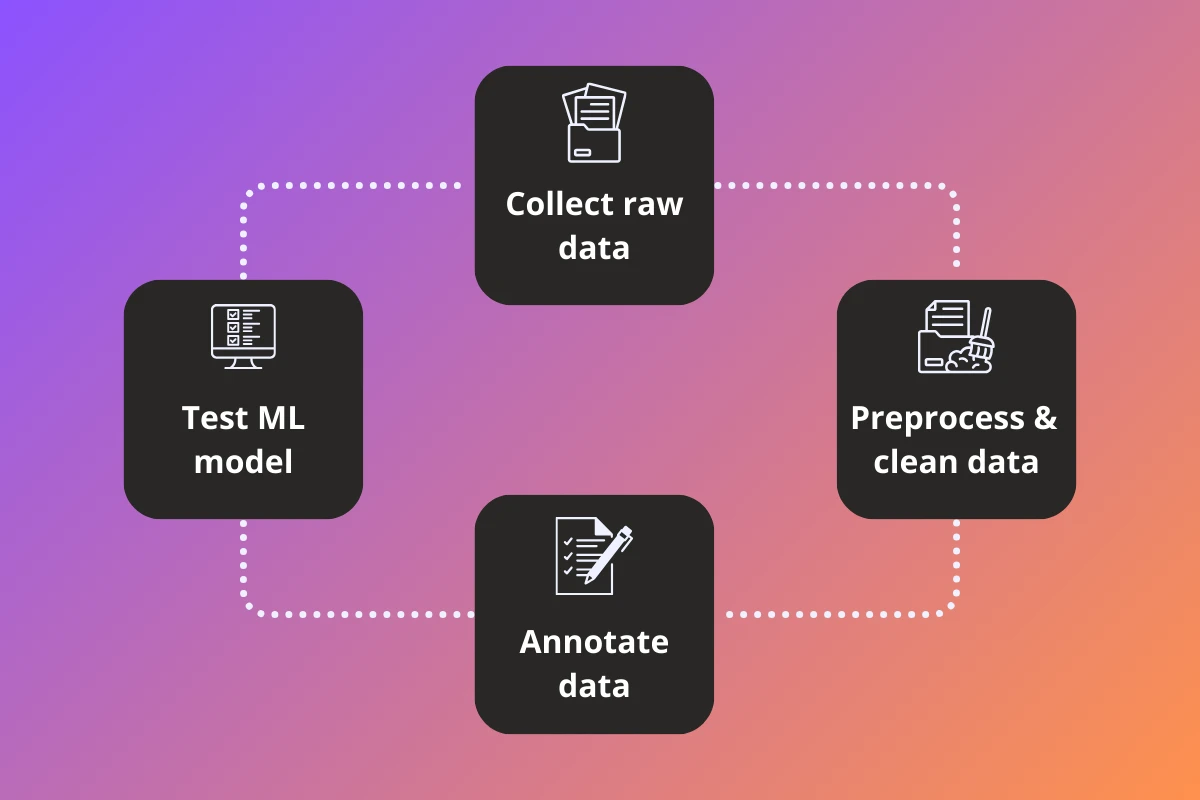
The data collection process in Machine Learning involves several steps. We briefly go through each of them below:
- Decide the overall strategy - Decide what kind of data is needed, how much of it is needed and how this data will be collected.
- Data collection - The actual data collection process. Various methods such as data mining, surveys, experiments or going out and collecting the data manually can be used to collect data.
- Data preprocessing - Once collected, the data needs be preprocessed to remove any noise, outliers, or inconsistencies. For example, you might want to remove overexposed or corrupt images.
- Data annotation - This preprocessed raw data needs to be annotated, which involves assigning meaningful tags or labels to the data. Data annotation is crucial for supervised learning algorithms, but can be skipped for unsupervised learning methods.
- Data augmentation - Finally, if the data volume is small, data augmentation techniques can be used to increase the amount and diversity of data by creating modified versions of the existing data. This also helps the model generalize by providing it varied data scenarios.
Data Sources
Depending on the Machine learning model's requirements, data sources can include public datasets, web scraping, social media, user-generated content, collecting sensor data etc. When choosing a data source, it is important to evaluate it's reliability, quality as well as legality. In some cases, the only option is to capture the data yourself - for example, if your use-case utilizes special sensors like LIDARs or cameras in specific locations. However, at-least for the experimental stage, you can find enough data publicly available.
Internal data sources
Internal data sources refer to the information generated within an organization. This could include data from sales transactions, customer interactions, operational processes, and other business activities. These also include generating data manually through various techniques. For example, if you want to create a dataset for detecting various types of fruits, you might send your team out to capture pictures of fruits. While this can be time-consuming and expensive, it provides two distinct advantages:
- Your data is specifically tailored for your use-case and captures the scenarios you are likely to encounter in the real world.
- Through this process you create a highly valuable data IP that can be the differentiator between you and your competitors.
External data sources
These source are those outside the organization's direct control. These could include public datasets, social media platforms, third-party data providers, and other online resources. Both internal and external data sources are critical for machine learning as they provide the raw material from which the algorithms learn and derive insights. The choice of data sources depends on the specific objectives of the machine learning project.
Dataset licenses

While publicly available datasets are highly valuable and can be a real asset, especially in the experimental phase, it is important to make sure you consider the legal side of using such datasets. Some datasets may not be available for commercial purposes at all. Others might warrant permission to be granted by the dataset owner. Here are some commonly found dataset licenses. Here is a brief description of the most popular dataset licenses in use today
- Public Domain: Datasets in the public domain are freely available to everyone for any use, without restriction.
- Creative Commons Zero (CC0): Very similar to the Public Domain license, but with some additional protections for the licensor, such as a waiver of moral rights.
- Open Data Commons Public Domain Dedication and License (ODC-PDDL): This license is specifically designed for datasets, and it is identical to the Public Domain.
- Creative Commons Attribution (CC BY): This license allows anyone to use, share, and adapt the dataset, as long as they give credit to the original creator.
- Open Data Commons Attribution License (ODC-BY): This license is similar to the CC BY license, but it is specifically designed for datasets.
- Creative Commons Attribution-NonCommercial (CC BY-NC): Allows users to copy, distribute, and modify the dataset, as long as they give credit to the original creator and do not use it for commercial purposes
Data Quality

Not all data is created equal. Poor data quality can lead to inaccurate predictions, biased outcomes, and ultimately, the failure of a Machine Learning project. Here’s a brief description of how to maintain data quality, focusing on handling missing data, cleaning the data and creating high quality annotations
Missing Data Handling
Missing data is inevitable in most datasets and can be a significant roadblock if not managed properly. Ignoring missing data or filling it with arbitrary values can skew the model's predictions. Instead, a structured approach is needed. Common techniques include:
- Imputation: Replacing missing values with mean, median, or mode can be effective for numerical data. For categorical data, the most frequent category might be a good substitute.
- Model-Based Methods: Sometimes, it's beneficial to predict missing values using other features in the dataset. For instance, using regression or more advanced techniques like k-Nearest Neighbors (k-NN) imputation can offer more accuracy.
- Deleting Rows/Columns: In cases where the missing data is minimal or the affected rows/columns are not critical, removing them might be the best option. However, this should be done cautiously to avoid losing valuable information.
Data Cleaning
When collecting data for Machine Learning, there will be a lot of unwanted data. It’s important to remove this data while making sure that the dataset is consistent and error-free. Here are the most popular methods to clean data :
- Remove Duplicates: This is very common when capturing data in form of videos. For e.g. if a car is waiting for the traffic light with little traffic, images captured during this time will be duplicates, which don't add any more value to the dataset. Duplicate entries can also skew the training process, leading to over-fitting or misrepresenting the data distribution.
- Outlier Detection and Handling: Detecting outliers serves two benefits:
- It can indicate to edge-cases which are very helpful in improving the performance of the ML model.
- It can help you detect faulty data. For e.g. outlier detection on exposure can help you identify over or under exposed images, which you might want to either completely remove or enhance before adding to the training dataset.
Creating high quality annotations
Once the dataset has been collected, in most cases the data then needs to be annotated. Depending on the use-case, annotation can involve labeling images, categorizing text, tagging objects in videos or 3D data like point clouds. Just like its important to ensure the collected data is of high quality, it is also important to make sure the annotations are of high quality. Maintaining the quality of annotations is a topic of discussion in itself. You can learn more about how to ensure high quality annotations here.
Synthetic Data Generation
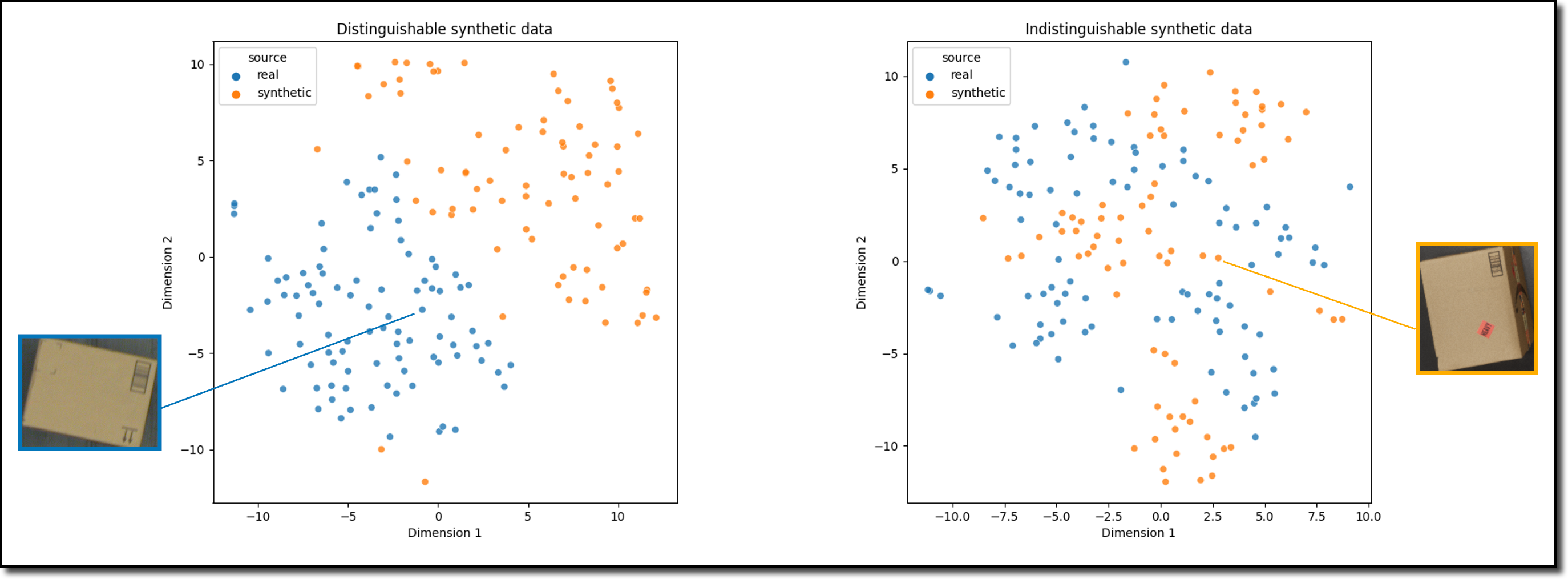
In situations where obtaining high-quality data is challenging, synthetic data can be a viable alternative. This involves generating data that mimics the properties and distribution of the real data, allowing model training without the risks associated with small, biased, or incomplete datasets.
- Generative Models: Techniques like Generative Adversarial Networks (GANs) can create realistic data points by learning the distribution of the actual dataset. This is specially useful in scenarios like image recognition, where generating labeled data can be time-consuming and expensive.
- Data Augmentation: For datasets that are smaller, augmenting the existing data by applying transformations like rotations, translations, or noise addition can effectively increase the dataset size and diversity, leading to more robust models.
Synthetic data generation is an active area of research, so it can be challenging to implement it properly for your use-case. However, if you can make it work, the upsides are tremendous.
Challenges in data collection for ML
As anyone who has undertaken the task of data collection can attest, collecting data for Machine Learning is not a straightforward task. It comes with challenges that can impact the quality, volume, and usability of the data. Let’s dig into some of the common hurdles faced during the data collection process.
Data Privacy and Ethics
Data privacy and security should be prioritized throughout the data collection and preparation process. Adequate measures must be in place to protect sensitive information, comply with relevant regulations (such as GDPR), and anonymize personal data if necessary.
It is also important to consider the ethical side of collecting or annotating data, specially if it is outsourced to external vendors. Always ask your vendors how their annotation teams are compensated, and what kind of working environment is provided to them.
Data Bias and Fairness
To develop robust and unbiased ML models, it is important to ensure that the training dataset is diverse and representative of the target population or the real-world scenarios the model will encounter. It is important to consider factors like demography, geographic locations, cultural backgrounds, and diverse perspectives. Proactively addressing underrepresented groups or potential biases helps in creating fair and inclusive AI models.
Continuous Iteration and Improvement
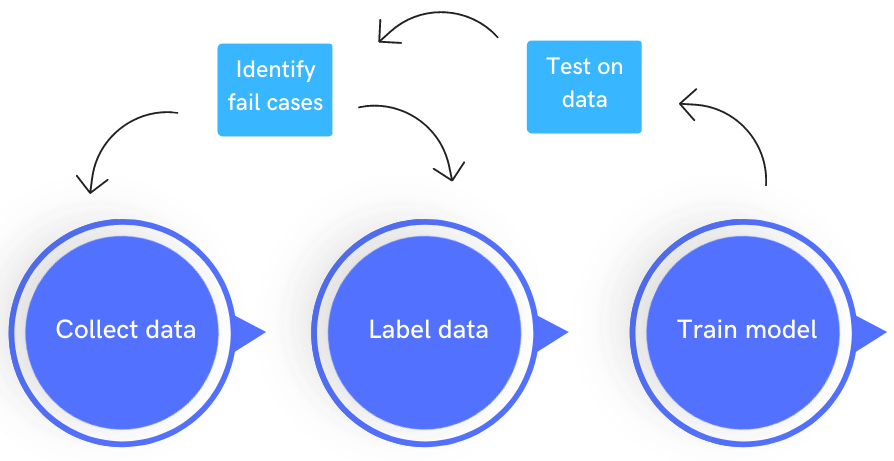
The process of collecting and preparing training data is not a one-time task. It requires continuous iteration and improvement. Feedback from AI model performance, user interactions, and real-world deployment should inform the refinement of training data. Updating and expanding the dataset over time helps the AI model stay relevant and adapt to changing conditions.
In recent years, there has been a growing shift from the traditional model-centric approach to improving ML performance to a more data-centric approach. The data centric approach to AI places importance on iteratively improving the data quality. This is a better approach to improving the Machine Learning model than trying to improve upon the algorithm, which in many cases, is already State of the art. You can learn more about Data Centric AI here
Conclusion
Collecting and preparing high-quality training data is crucial for the success of ML models. By defining clear objectives, determining relevant data sources, ensuring data diversity and representation, cleaning and preprocessing data, and addressing privacy and ethical considerations, developers can create effective and unbiased AI systems. Continuous iteration and improvement further enhance the model's performance. By following these strategies, AI can be empowered with training data that drives accurate predictions, robust decision-making, and positive impacts on society.



