A common joke in the Machine Learning community is that about 80% of machine learning is simply data cleaning. While statistics - Machine Learning's distant cousin - places huge importance on data, ML seems to focus on the algorithms that operate on that data. Another startling fact is that almost 90% of ML models globally are never brought to light. This can largely be attributed to the fact that real world data can differ significantly from the data the models are trained on - a problem more generally known as that of Generalization. While a lot of companies are spending up-to 12 months to build their ML models, very few are actually getting to use those models in real life. One thing is clear: Data is critical. (Something we at Mindkosh have believed in from day one!)
Building and Deploying ML - MLOps
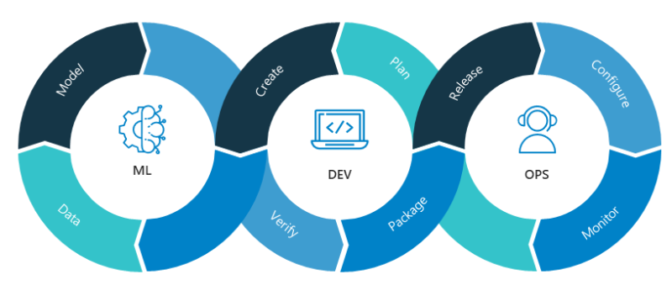
MLOps is concerned with building and deploying machine learning models more systematically. Andrew Ng, its most vocal proponet and a stalwart of the ML Community believes that focusing on data, instead of only working on improving one's code, could unlock multitudes of new multimillion-dollar applications of artificial intelligence. He claims that current architectures are highly evolved for identifying photographs, recognizing speech or generating text. Tinkering with their architecture is perhaps not the best method to enable them to perform better anymore.
Unlike traditional software systems that are mainly powered by code, AI systems are a combination of Algorithms(code) and Data. But while a great of deal of importance is placed on building better models, improving data quality is largely confined to basic pre-processing routines.
Is data really that important?
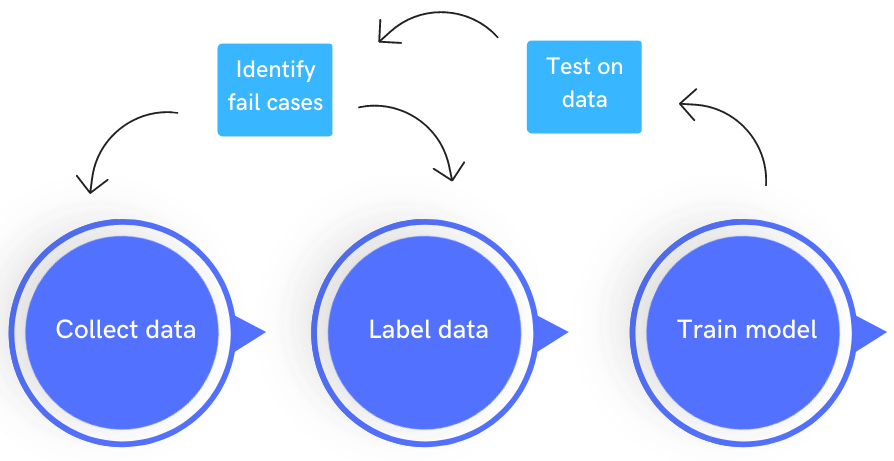
Yes. It really is. To drive home the importance of improving the quality of data, it can be argued that data could be the answer to some of the major challenges AI currently faces. Reducing the amount of data needed to train a typical ML model from millions to tens of thousands is one of them. Another is learning to understand when humans do not agree - like when different medical experts come up with different diagnoses. Some others are - identifying inconsistency among data sources, changes in data over time due to changes in behavior, and creating useful synthetic data when real world data is not readily available.
While small datasets struggle with noisy data, large volumes of data make labeling difficult. For use cases where expert knowledge is required - like medical diagnoses - access to such field experts can be a huge bottleneck for collecting high-quality labels. Another big challenge in moving trained ML models from development to use in the real world, is to have enough variance in the training data, so that the model can learn higher level concepts rather than learn by rote.
From our experience here are Mindkosh, there are two keys to handling large volumes of data
- Use a labeling tool that allows collaboration between labelers
- Build a team of labelers and project managers that are experienced enough to avoid the usual mistakes committed in labeling certain kinds of datasets.
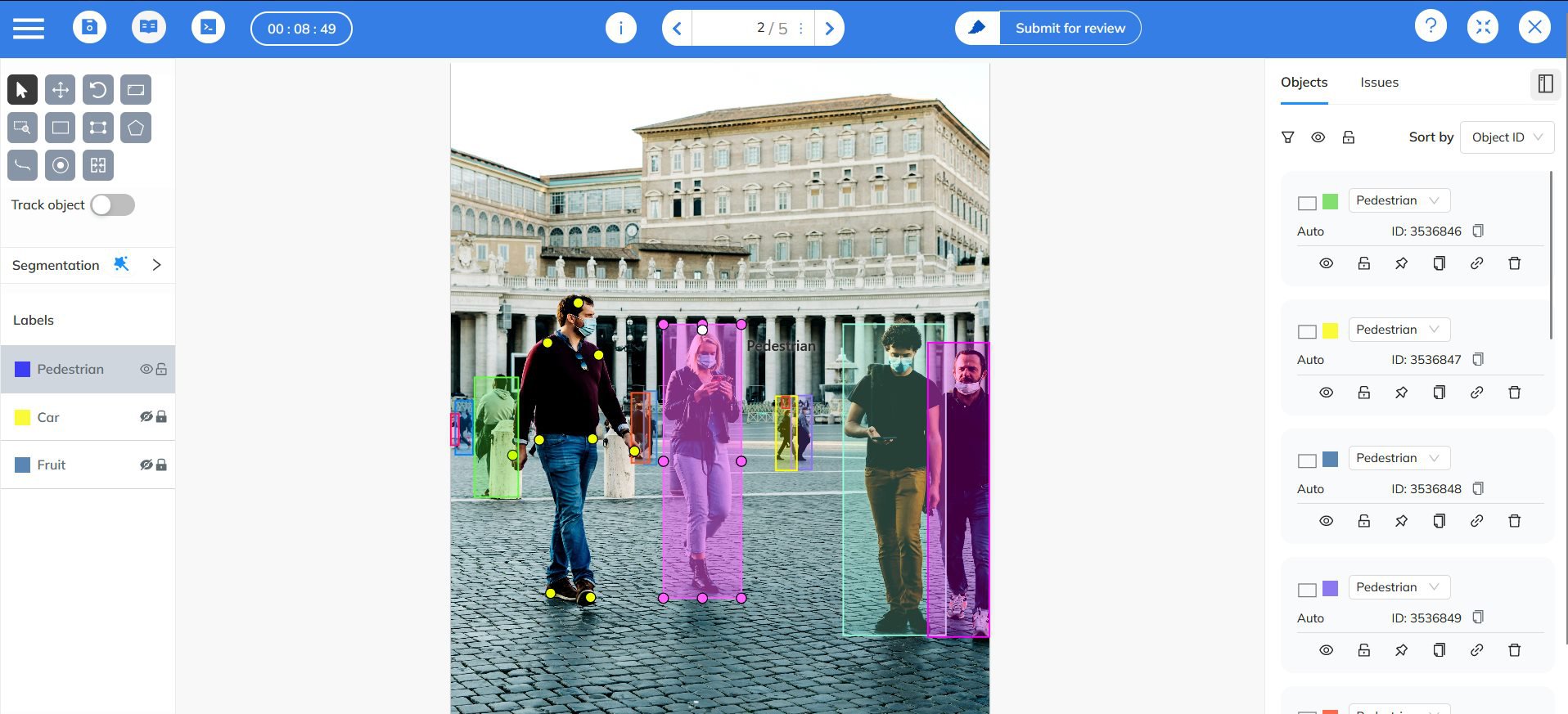
So what can we do to address these problems?
Follow the core principles of MLOps as laid down by Andrew Ng. The most important task of MLOps is to make high-quality data available.
Labeling consistency is key
It is important to check up on how your labelers are marking things like bounding boxes, which could be tighter or loser across the dataset. Whatever strategy you choose, make sure that it is consistent across the entire dataset. At Mindkosh, we make sure the annotation guidelines are perfectly clear to all labelers and reviewers. A good way to achieve this is to have clear lines of communication between the labelers and the model owners, through slack channels. By allowing reviewers to mark the parts of data they feel could be better, we also make sure all stakeholders are on the same page.
Data over state-of-the-art models
Systematic improvement of data quality on a basic model is better than chasing state-of-the-art models with low-quality data. While chasing better models is beneficial if you are writing a research paper, it is generally better to work on data if your aim is to deploy the model in the real world.
Handling errors
In case of errors during training, take a data-centric approach. One way to address errors can be to get your data labeled in an iterative fashion - where you train your data in batches, while identifying potential issues in the data.
Dealing with small datasets
When working with smaller datasets (<10k examples), tools and services to promote data quality are critical. For these datasets where noise can be a big problem, every mis-labeled object can cause the model to under-perform.
Keeping these tips in mind, last month we launched our Data Curation pipeline to help ML engineers and Data scientists curate their datasets better. By making sure that the dataset includes important edge cases and that it is free of dangerous biases, we help you squeeze the most out of your Ground truth data.




