
In the realm of machine learning (ML) and artificial intelligence (AI), the adage "garbage in, garbage out" holds particularly true. The quality of a model's predictions is intrinsically tied to the quality of the data it's trained on. One critical aspect of ensuring high-quality data is accurate labeling. However, human annotators, being inherently subjective, can introduce inconsistencies and biases into datasets. This is where multi-annotator validation comes into play.
Multi-annotator validation involves collecting labels from multiple annotators for the same data points and consolidating them to achieve a more accurate and unbiased consensus. This approach is especially vital in complex domains like Healthcare, Natural Language Processing (NLP), and Autonomous driving, where even minor labeling errors can lead to significant model performance issues.

Core Concepts
Majority voting
The simplest method of achieving consensus among multiple annotators is majority voting. Here, the label that receives the most votes from annotators is assigned as the final label.
- Pros:
- Straightforward implementation
- Effective when annotators have similar expertise levels
- Cons:
- Doesn't account for annotator reliability
- May not handle ambiguous cases well
Label aggregation techniques
Beyond majority voting, more sophisticated methods consider annotator reliability and task complexity:
- Bayesian Models: Estimate the probability of each label being correct, considering annotator performance.
- Dawid-Skene Algorithm: Weighs annotators differently based on their historical accuracy.
- Probabilistic Fusion Methods: Combine labels probabilistically to account for uncertainty.
These techniques are particularly useful in high-stakes fields like medical imaging and autonomous vehicle data annotation, where accuracy is paramount.
Inter-annotator agreement
Measuring how consistently annotators label the same data points is crucial. Common metrics include:
- Cohen’s Kappa: Measures agreement between two annotators, adjusting for chance.
- Fleiss’ Kappa: Extends Cohen’s Kappa for more than two annotators.
- Krippendorff’s Alpha: Handles multiple annotators and missing data, suitable for various data types.
High agreement scores indicate reliable annotations, while low scores may signal the need for clearer guidelines or additional training. We have described these Inter-annotator agreement techniques in more detail here.
Annotator expertise and bias
Annotator performance can vary due to factors like domain expertise, fatigue, or personal biases. To mitigate these issues:
- Weight Annotations: Assign higher weights to annotations from more experienced annotators.
- Monitor Label Confusion Trends: Identify patterns where annotators consistently mislabel certain categories.
- Rotate Tasks: Prevent fatigue and over-familiarity by rotating annotators across different tasks.
Choosing the right annotation tool
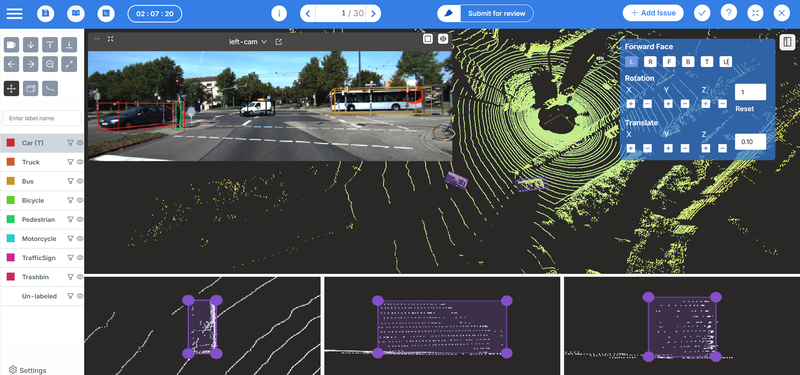
On a practical level, maintaining accuracy, consistency, and accountability across contributors can quickly become a challenge in multi-annotator projects. Different annotators may interpret data in slightly different ways, and without proper tools to manage this complexity, teams risk introducing errors or losing valuable context. Choosing the right annotation tool is therefore essential — one that not only supports collaboration but also provides robust version control and an efficient quality assurance workflow.
Our annotation tool is purpose-built to handle these challenges in large-scale, multi-annotator setups. It allows project managers to easily create and assign tasks to multiple annotators, ensuring that every contributor’s work is kept separate and traceable. Each annotator’s version of an annotation is maintained independently, preserving their unique input without the risk of overwriting or confusion. This structure makes it simple to compare annotations, identify inconsistencies, and gather insights into how different annotators approached the same data.
Once annotations are complete, quality assurance (QA) specialists can review all submitted versions and select the one that best represents the desired standard. The chosen version can then be designated as the final ground truth. This workflow not only enhances annotation quality and transparency but also accelerates the review cycle — making Mindkosh an ideal choice for teams managing complex, collaborative annotation projects.
More advanced topics
Annotator confusion matrices
Confusion matrices help identify patterns where annotators consistently confuse certain labels. This analysis can:
- Highlight areas where annotation guidelines need clarification
- Identify annotators who may require additional training
- Feed into AI-driven scoring systems to assess annotator performance
Ground truth estimation
In scenarios where a definitive "ground truth" is unknown, consensus among annotators serves as a proxy. Methods include:
- Expectation-Maximization (EM): Iteratively estimates the most probable true labels.
- Weighted Voting: Considers annotator reliability when aggregating labels.
- Gold-Standard Verification: Compares consensus labels against a subset of expertly labeled data.
Label noise and uncertainty
Noisy labels can degrade model performance. Techniques to address this include:
- Label Smoothing: Prevents the model from becoming overconfident by softening hard labels.
- Reweighting: Assigns lower weights to ambiguous labels during training.
- Uncertainty-aware Learning: Trains models to account for uncertainty in labels.
Annotation process optimization
In general, optimizing the annotation process can lead to better label quality. Here are some tips on how to make your annotation pipeline more efficient. You can learn more here.
- Clear Instructions: Provide detailed guidelines to reduce ambiguity.
- User Interface (UI) Design: Use annotation tools that make it easy to perform QC, communicate with the team and manage the tasks in a more organized manner. You can check out our annotation tool which handles all this and more.
- Feedback Mechanisms: Allow annotators to flag uncertain cases or suggest improvements.
Practical applications

Crowdsourcing and annotation networks
Platforms like Amazon Mechanical Turk leverage crowdsourcing to scale data annotation. They implement multi-annotator validation by:
- Assigning the same task to multiple annotators
- Aggregating labels using consensus algorithms
- Implementing quality control measures to ensure data reliability
Large-scale projects like ImageNet and Open Images have successfully utilized these strategies to build extensive datasets. Crowdsourcing is a cheap solution to the data annotation problem, but the quality of data is often low due to the un-managed nature of the annotation process. While multi-annotator setups cannot alleviate some of these quality issues, they can quickly get more expensive, which erodes the prime benefit provided by crowdsourcing - which is cost-effectiveness. You can check out prices for our fully managed annotation services here.
Creating golden datasets and choosing annotators
Multi-annotator validation can also be helpful in creating a golden ground truth dataset with very high quality labels. These labels can then serve as the North star to train labelers, or to measure the quality of any further labeling tasks using a method called Honeypot.
It can also be helpful to choose the right annotator team for complex tasks which may require some domain knowledge. In fact in some scenarios, the task may inherently be ambiguous, in which case multi-annotator setups may be the only way to label the datasets with high quality. Tasks involving natural text such as those relating with LLMs and NLP fall in this category.
Conclusion
Multi-annotator validation is more than a quality assurance step; it's a fundamental component of reliable machine learning workflows. By incorporating consensus methods, measuring inter-annotator agreement, and optimizing annotation processes, organizations can significantly enhance the accuracy and consistency of their datasets.
As AI applications continue to expand into critical domains, the importance of high-quality data annotation cannot be overstated. Implementing robust multi-annotator validation strategies ensures that models are trained on data that truly reflects the complexities of the real world, leading to more trustworthy and effective AI systems.



