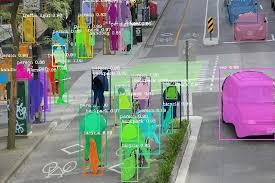
Autonomous vehicles (AVs) represent one of the most transformative innovations in modern transportation. These systems rely heavily on computer vision to perceive and understand their environment—identifying lane markings, detecting pedestrians, recognizing traffic signs, and making split-second decisions. But what enables these machine vision systems to work so effectively?
The answer lies in data annotation.
Every decision an AV makes is grounded in learning from annotated datasets comprising thousands of labeled images, LiDAR point clouds, and radar scans. These annotations instruct machine learning models on how to interpret raw sensor data, enabling them to distinguish between various elements, including vehicles, pedestrians, roads, and numerous other components in complex driving environments.
In this blog, we explore how data annotation plays a pivotal role in empowering computer vision systems within AVs. We’ll look into the various sensor inputs, annotation techniques, quality requirements, and the challenges of ensuring accuracy in safety-critical applications.
Vision systems in autonomous vehicles: The inputs
AVs use a combination of sensors to capture a complete picture of their surroundings. Each sensor brings a unique perspective and demands specific types of annotation for model training.
Camera data for object detection
Cameras are the most human-like sensors used in AVs. They capture high-resolution RGB images that provide essential information such as color, texture, shape, and visual contrast. Camera feeds are crucial for tasks like:
- Reading traffic signs and signals
- Detecting lane markings
- Recognizing vehicles, pedestrians, bicycles, and animals
- Interpreting road conditions and hazards
To train models on camera data, annotators use a range of techniques, including:
- Bounding boxes: Rectangular annotations that highlight objects like cars or people in an image.
- Polygon segmentation: Precise outlines drawn around objects to capture their exact shape.
- Keypoint annotation: Marking specific landmarks or joints (e.g., knees, elbows, wheels) to analyze object posture or orientation.
These annotations must be applied across thousands of frames, requiring consistency and accuracy to ensure that models learn to recognize and differentiate objects in varying lighting and environmental conditions.
LiDAR and radar for depth and obstacle sensing
LiDAR (Light Detection and Ranging) sensors emit laser pulses to create 3D point clouds of the environment. Unlike 2D images, LiDAR provides accurate depth perception and geometric structure, making it ideal for:
- Measuring distances to objects
- Identifying curbs, poles, and road edges
- Mapping 3D positions of vehicles and pedestrians
- Navigating complex terrains
Annotating LiDAR data involves techniques such as:
- 3D cuboid annotation: Creating bounding boxes around objects in 3D space.
- Semantic segmentation: Labeling each point in the cloud with a category like road, car, pedestrian, or vegetation.
Radar, on the other hand, is more resilient in poor visibility conditions (rain, fog, darkness). While it offers less detail than LiDAR, it enhances the robustness of the AV's perception system. Annotating radar data involves identifying object returns and associating them with known categories, especially for moving objects.
Sensor fusion: Multi-modal labeling
No single sensor can guarantee perfect perception. AVs use sensor fusion to combine data from multiple sources—such as cameras, LiDAR, radar, and GPS—to improve accuracy and reduce uncertainty.
Multi-sensor data annotation involves:
- Synchronizing timestamps across sensor streams
- Aligning coordinate systems between 2D and 3D data
- Projecting labels from one modality (e.g., a 3D cuboid in LiDAR) onto another (e.g., a camera image)
This fusion process requires advanced platforms that can handle cross-modality annotation and ensure that labels are coherent across different sensor views. This is particularly important in complex scenes with moving objects or occlusions.

Annotating the vision: Techniques that train the model
Once sensor data is collected, the next step is annotation—a process that translates raw inputs into structured, labeled data suitable for machine learning.
Bounding box and instance segmentation
Bounding boxes are among the most fundamental annotation types. They provide a quick and efficient way to teach models about object localization and classification. For example, by labeling thousands of cars, stop signs, and pedestrians with bounding boxes, AV models learn to identify these objects in real time.
However, bounding boxes have limitations—especially in cluttered or complex scenes. That’s where instance segmentation comes in. This technique not only detects objects but also separates them from the background and from other similar objects. It's essential for differentiating between overlapping entities, such as two pedestrians standing side by side.
Accurate instance segmentation allows AVs to:
- Maintain safe distances from individual road users
- Navigate through densely populated areas
- Handle occlusions and partial visibility
Interpolation and object tracking
Driving is a continuous process, not a sequence of still images. Models must understand how objects move over time. Annotating video sequences for object tracking ensures that the same object is consistently labeled across frames, helping the model understand motion patterns.
Interpolation is used to automate part of the tracking process. By annotating a few keyframes and using software to predict labels in intermediate frames, annotators can save time and ensure temporal consistency.
Tracking annotations help AVs:
- Predict pedestrian paths
- Avoid collisions with moving vehicles
- Understand acceleration, deceleration, and trajectory
Pre-annotation and quality assurance
As datasets grow in size and complexity, manual annotation becomes increasingly resource-intensive. Pre-annotation—where AI tools generate initial labels—can significantly accelerate the process. Human annotators then verify and correct these suggestions, combining the speed of automation with human accuracy.
High-quality annotation platforms also support robust quality assurance (QA) workflows. These include:
- Consensus checks among multiple annotators
- Review layers for supervisor approval
- Honeypot validations where known labels are inserted to measure annotator performance
These techniques ensure that the final dataset is not only fast to produce but also trustworthy for training critical models.
The cost of poor annotations
In autonomous vehicles, a labeling error is not just a data issue—it can become a safety issue. Incorrect or inconsistent annotations can lead to poor model performance, and in the worst cases, dangerous real-world decisions.
Examples of critical failures due to poor annotation include:
- Misidentifying a pedestrian as background.
- Missing a stop sign, partially obscured by tree branches.
- Failing to detect bicycles due to inadequate training examples.
Poor annotations often lead to:
- False positives (e.g., seeing an object that isn’t there)
- False negatives (e.g., missing real obstacles)
- Erratic driving behavior (e.g., sudden braking or swerving)
That’s why annotation must meet strict criteria:
- Accuracy: Every label must match the object with precision—whether it’s in 2D or 3D.
- Consistency: Annotations must remain uniform across frames and similar scenes.
- Validation: Every dataset must go through rigorous QA before being fed into a training pipeline.
Even small inconsistencies—like labeling “bicycle” in some frames and “bike” in others—can confuse learning algorithms and reduce model reliability.

Conclusion
The road to full autonomy doesn’t just rely on better hardware or faster processors—it depends on better data. Specifically, it depends on how well we annotate that data.
Computer vision in autonomous vehicles thrives on:
- Multi-sensor input: Cameras, LiDAR, radar, GPS—all integrated to provide full environmental awareness.
- Advanced annotation techniques: Bounding boxes, segmentation, tracking, and fusion annotations that make sense of complex scenes.
- Robust QA systems: Ensuring that every labeled object reflects the reality it represents.
As the industry advances, annotation workflows are evolving too. Pre-annotation pipelines, AI-assisted labeling, and real-time QA tools are making it easier to label vast datasets quickly and accurately. Annotation platforms built for scalability and precision are becoming indispensable for companies developing the future of mobility.
In the end, the intelligence of an autonomous vehicle is only as good as the data it learns from. By investing in high-quality data annotation, we’re not just teaching machines to drive—we’re shaping the safety and success of next-generation transportation.