
Object detection and image segmentation are fundamental techniques in computer vision, used to interpret and analyze images in various applications. This article provides an in-depth look at these methods, discussing their unique roles, methodologies, and challenges.
Object detection and Image segmentation
In computer vision, both object detection and image segmentation play critical roles. However, they are applied differently, focusing on distinct objectives within image analysis.
What is image segmentation?
Image segmentation divides an image into multiple segments to identify individual objects or regions. This process involves assigning a label to every pixel, enabling a detailed understanding of object boundaries and shapes within an image. Segmentation can be further categorized as:
- Semantic segmentation: Assigns a class label to each pixel without distinguishing between different instances of the same object class.
- Instance segmentation: Identifies and distinguishes multiple instances of the same object within an image. You can learn more about the difference between Semantic and Instance segmentation here.
For example, in a scene with multiple cars, instance segmentation will label each car separately, while semantic segmentation may simply label all pixels corresponding to "car."
What is object detection?
Object detection identifies and classifies objects within an image, typically by drawing bounding boxes around each detected object. The bounding boxes, paired with classification, allow the model to locate and label specific objects, such as cars, pedestrians, or animals. Object detection has significant applications in areas that require real-time analysis and localization, such as autonomous driving and security.
Object detection and image segmentation: Deep learning approaches
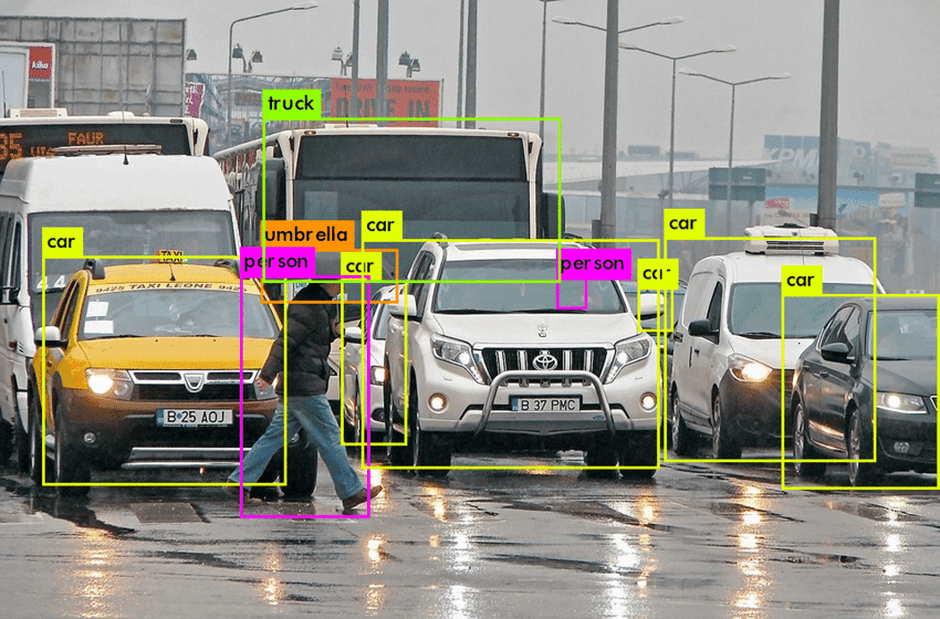
Modern computer vision relies heavily on deep learning for both object detection and image segmentation. Some common approaches include:
- Object detection: Convolutional Neural Networks (CNNs) and Region-based CNNs (R-CNN, Fast R-CNN) are used for object detection, where layers learn spatial hierarchies of features.
- Image segmentation: Methods like Fully Convolutional Networks (FCN) and U-Net are popular in segmentation, as they provide detailed pixel-level classification essential for medical imaging and environmental mapping.
By leveraging deep learning, both techniques can improve in accuracy and efficiency, with models that can be trained on large datasets like COCO and ImageNet.
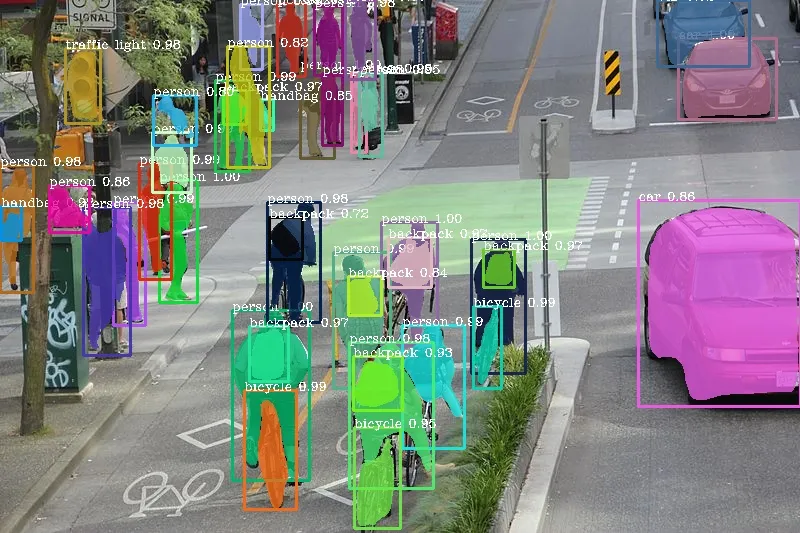
High-level semantic features
Object detection and Image segmentation both utilize features in unique ways:
- Object detection: Primarily relies on high-level semantic features to identify and locate objects. This is achieved through feature maps and bounding box coordinates.
- Image segmentation: Focuses on pixel-level details for precise boundary delineation, making use of both high-level semantic and low-level spatial features for accurate segmentation.
While object detection is more concerned with identifying and categorizing objects, image segmentation emphasizes fine detail and edge accuracy.
Performance strategies
Performance strategies for object detection
Improving object detection performance involves strategies such as:
- Optimizing Feature Maps: High-resolution feature maps provide better accuracy, particularly for detecting smaller objects.
- Pooling Layers: Advanced pooling methods, like spatial pyramid pooling, help preserve spatial information across varying resolutions.
Performance strategies for image segmentation
Enhancing image segmentation accuracy often includes:
- Refinement of Boundaries: Techniques like conditional random fields (CRFs) help refine pixel boundaries.
- High-resolution Layers: Keeping high-resolution layers active in the network can improve segmentation results, particularly in dense scenes.
Both object detection and segmentation benefit from careful network architecture selection, balancing resolution and processing speed.
Key challenges
Challenges in object detection
Object detection challenges include:
- Boundary Precision: Bounding boxes can be inaccurate for irregularly shaped objects, leading to less precise object localization.
- Class Imbalance: Detection can struggle with rare object classes in datasets, affecting accuracy.
Challenges in image segmentation
Image segmentation faces unique challenges, such as:
- Computational Intensity: Segmentation requires significant computational power due to pixel-level labeling.
- Occlusion Handling: Segmenting objects that are partially hidden is complex, especially in dynamic scenes.
Overcoming these challenges requires optimization of computational resources and innovative algorithmic solutions.
Applications and use-cases
Image analysis and video surveillance
Both techniques are integral to image analysis and video surveillance. Object detection helps track objects, while segmentation provides detailed insights, such as identifying object boundaries and shapes in surveillance footage. The COCO dataset serves as a benchmark for both techniques, enhancing accuracy in challenging scenarios.
Specific object identification
Applications such as autonomous driving and medical imaging rely heavily on object detection and segmentation. In autonomous driving, segmentation identifies drivable areas and lanes, while object detection tracks vehicles and pedestrians. In medical imaging, segmentation delineates organs or tissues, whereas detection highlights specific abnormalities or markers.
Object detection and image segmentation: Which is right for you?
Object detection and image segmentation are complementary techniques, each excelling in different aspects of computer vision. Object detection is effective for locating objects in real-time, while image segmentation provides detailed image information crucial for applications requiring fine resolution. Together, these methods provide a complete framework for understanding and analyzing visual data.
By understanding their differences, you can better decide which technique suits specific applications and contexts in computer vision, leveraging both for more comprehensive image analysis.



