Most multimodal annotation workflows don’t fail loudly. They fail quietly.
During pilots, everything looks stable. Teams label camera data, LiDAR point clouds, depth maps, and Radar data. Models train. Metrics improve. Stakeholders feel confident enough to move forward.
Then the system reaches production. Suddenly, the data is no longer feeding experiments. It is driving real systems. Real decisions. Real costs. Sometimes, real safety outcomes. This is where small cracks start to matter.
Multimodal annotation simply means labeling data from multiple sources together. In production, those labels are no longer theoretical. They shape deployed models, customer experiences, and operational accountability. Mistakes don’t stay in experiments—they show up as delays, rework, and lost confidence.
Across autonomy, robotics, Geospatial systems, and medical imaging, the pattern is the same. Workflows that worked in pilots begin to strain, not because teams fail, but because the annotation systems were never built for production-scale multimodal complexity.
What breaks first is not the team. It’s the annotation system.
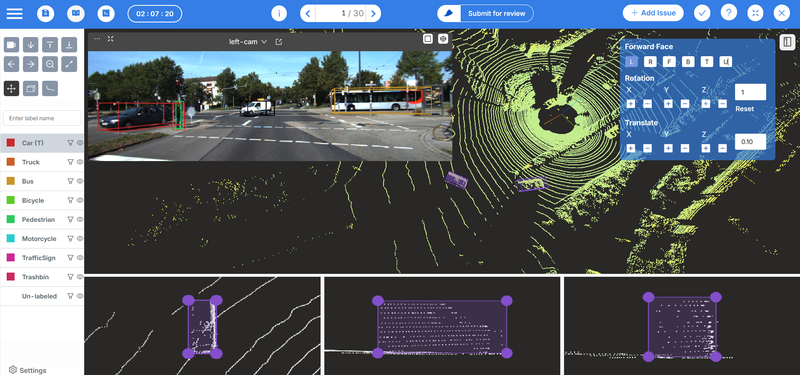
Labels stop meaning the same thing across data sources
In the early stages, teams often label each data type separately. Camera images in one tool. LiDAR point clouds in another. Depth or sensor data somewhere else. Each workflow makes sense on its own.
The problem appears when those labels are expected to work together.
Different sensors produce different views of the same object. A car looks like a clean rectangle in a camera image. In LiDAR, it becomes a sparse cloud of points. Each view is valid but is not identical.
When these views are labeled independently, the meaning of a “car” slowly diverges. Boundaries don’t align, and edge cases are interpreted inconsistently.
In autonomy, this manifests as camera annotations appearing clean, but when compared with LiDAR, object boundaries no longer line up. Teams end up debating the model, the sensor, or the data—when the real issue is that the system never forced those views to agree.
The stakes are even higher in medical imaging. The same structure can look clear in one scan and ambiguous in another. When labeled separately, those differences carry into the model, increasing the risk of missed or incorrect interpretations—where annotation quality is critical.
Teams often respond by tightening guidelines or retraining annotators. But this isn’t a human problem. It’s a system problem. Without a unified way to label multiple modalities together, consistency becomes a matter of manual coordination. And manual coordination breaks in production.
Sensor fusion-heavy systems like autonomy and robotics expose this failure fastest, because they depend on tight alignment between 2D and 3D data. Platforms built specifically for these workflows handle that linkage by design, rather than treating each sensor as a separate problem. Platforms designed for multimodal work treat these data sources as one system, not parallel tracks. Consistency is enforced by design, not by memory or repeated instructions.
Review effort grows, but confidence shrinks
As multimodal complexity increases, so do edge cases. Objects are partially visible in one sensor and clear in another. Conflicting signals between data sources. Ambiguous situations that don’t fit neatly into predefined categories.
The most common response is to add more reviews. At first, this feels responsible. More eyes should mean better quality. In practice, the opposite often happens. Reviewers encounter the same ambiguous cases repeatedly. Decisions get revisited without resolution. Disagreements circulate instead of converging. Teams spend more time reviewing but trust the data less.
This paradox shows up clearly in production systems. In autonomy, rare road scenarios slip through despite heavy review processes slowing progress without increasing confidence.
The issue is not effort. It’s focus. Traditional review models assume all data deserves equal attention. In multimodal production environments, that assumption breaks down. What matters is uncertainty. Where sensors disagree, and decisions require judgment.
Validation-first workflows are built around this reality. Instead of checking everything later, they surface uncertainty early. Reviewers focus on the cases that actually need human judgment. In production environments, quality has to be designed into the process itself. Validation works best when it enforces standards as data is created, not when it tries to correct errors after the fact.
Confidence grows not because more data is reviewed, but because the right data is reviewed.
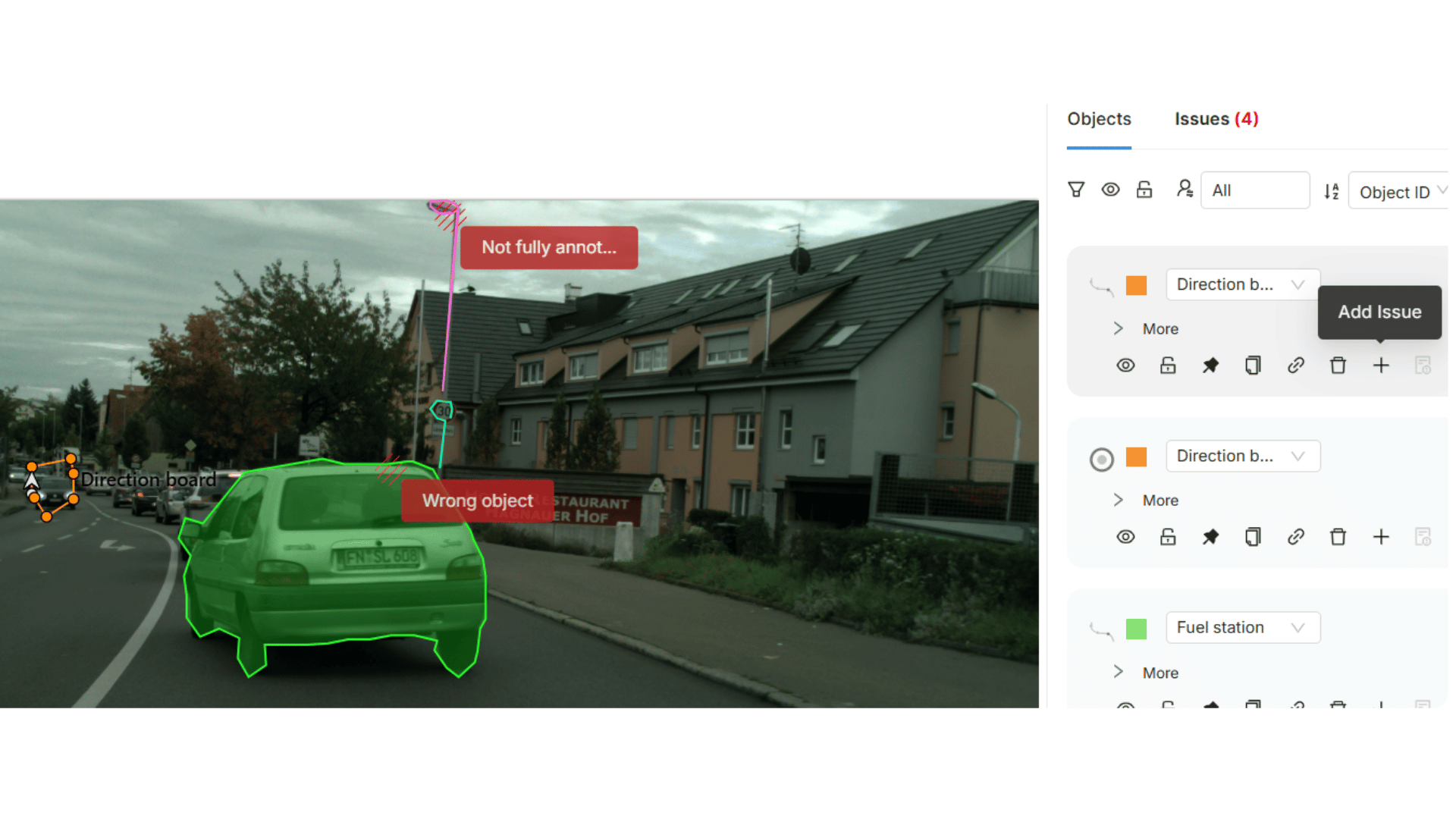
Disagreements are discovered too late
One of the most expensive failures in production annotation is late discovery.
Late discovery means teams assume labels are correct until something downstream breaks. A model behaves unpredictably, and performance metrics stall. A deployment test fails.
Only then does the investigation begin. By that point, the cost is already high. Data must be traced back. Labels re-examined. Entire datasets are sometimes reworked. Timelines slip, and trust erodes.
In robotics, this shows up as repeated retraining driven by subtle labeling inconsistencies. The robot hesitates on familiar tasks, fails in new situations, or requires overly conservative safety limits—slowing deployment and reducing confidence in real-world operation.
Late discovery is expensive because problems compound over time. Small disagreements that could have been resolved early turn into systemic failures when embedded deep in production pipelines.
Production-ready systems are designed to surface disagreement during annotation, not after deployment. They make conflicts visible when they are still cheap to fix. When decisions can be discussed, documented, and resolved before they affect models and delivery schedules.
Quality becomes inconsistent across teams and time
Production brings parallelism. Internal teams work alongside external vendors. New annotators join. Projects run across months or years. Guidelines evolve, and context fades.
Early decisions that once felt obvious become unclear. Without a system to preserve and enforce those decisions, quality slowly drifts. Today's labels no longer match last quarter’s labels, even though the project hasn’t fundamentally changed.
This inconsistency is especially risky in regulated or safety-critical domains. In autonomy and robotics, differences between internal and external labeling teams can introduce unpredictable behavior. In medical imaging, annotation standards vary across clinical partners, undermining trust in aggregated datasets.
Consistency over time is not about freezing rules forever but about ensuring that changes are deliberate, visible, and applied uniformly. Production teams need workflows that can evolve deliberately—where annotation logic and guidelines change as requirements change, without breaking continuity or introducing ambiguity.
Platforms like Mindkosh that combine tooling with managed services help maintain this continuity. The same workflows, quality rules, and validation logic apply regardless of who is doing the work. Institutional knowledge lives in the system as well, not just with the people.
Quality assurance starts slowing down delivery
At some point, quality assurance stops feeling like protection and starts feeling like a bottleneck. Ops leaders face an uncomfortable tradeoff. Push data through faster and reduce the risk of mistakes. Slow down for QA and miss delivery targets.
This tension creates friction across teams. Engineering wants data now. QA wants more time. Leadership wants both speed and confidence. This is not a tooling inconvenience. It’s a leadership problem.
At this stage, teams also need clear operational control—visibility into quality without disrupting work and oversight without introducing risk to the annotation process itself.
When quality is treated as a final gate, it will always slow down delivery. Production systems require a different approach. Quality must be embedded into the workflow itself. Checks happen as work is done, not after the fact.
When QA enables speed instead of blocking it, teams no longer have to choose between trust and timelines.
How teams avoid these failures with multimodal annotation
Teams that scale multimodal annotation successfully follow a few consistent patterns.
They use one system instead of fragmented tools, so multiple data types are handled together rather than reconciled later. Quality issues are surfaced during annotation, not discovered during model failure, with reviewers focused on uncertainty instead of volume.
Consistency is enforced by the workflow itself—even as requirements evolve—rather than relying on memory or static guidelines.
These patterns reflect a simple truth: production annotation requires systems designed for change, quality, and accountability, not pilot-era workflows.
Where Mindkosh fits
Mindkosh is designed for teams at this exact stage.
Teams that have crossed the line from experimentation into production, where multimodal data, delivery pressure, and quality risk collide. Mindkosh offers a complete platform for labeling images, videos, and LiDAR data all in one place, making sure everything is consistent across different sensors.
With a quality-first annotation approach, Mindkosh embeds validation directly into the workflow. AI-assisted tools like pre-annotation, interactive segmentation, and cuboid labeling improve consistency while surfacing uncertainty early before issues appear in models or deployments.
Flexible annotation workflows allow guidelines to evolve without introducing drift, while managed annotation services ensure the same standards apply across teams and over time.
Crucially, this holds from pilot to scale. Mindkosh uses production-grade validation from the start, so what works in a pilot is precisely what runs in production. Multimodal systems don’t break because teams scale—they break when fragile annotation workflows meet production reality. Mindkosh is designed for that transition.