
Scaling annotation pipelines usually starts with optimism.
More data is coming in. Models need to be trained faster. Teams expand, tools get upgraded, and throughput increases. On the surface, everything looks like progress. Datasets grow. Annotation velocity improves. Milestones are met.
Then something subtle begins to happen.
Labels that once felt reliable start to feel inconsistent. Review cycles stretch longer. Model results become harder to explain. Teams spend more time debating data than moving forward.
This is the moment many ops and program managers recognize a hard truth: scaling annotation is easy; scaling consistency is not.
Scaling annotation compromises quality
In small teams, annotation works largely because of shared context. Everyone understands what labels mean. Edge cases are discussed informally. When something looks unclear, someone asks a question and moves on.
As pipelines scale, that shared understanding fragments.
New annotators join with limited context. Definitions are interpreted slightly differently. Exceptions that were once rare become common. Decisions made early in the project aren’t always visible to people working on the data months later.
None of this looks like failure at first. Output volume remains high. Reviews still happen. Models still train.
But consistency—the thing that makes labeled data reliable over time—begins to erode.
For ops teams, this is dangerous territory. Label inconsistency doesn’t usually trigger an alert. It shows up indirectly. Unstable model behavior, conflicting results between datasets, and long investigation cycles trying to trace issues back to their source follow. Left unchecked, it can cause serious problems, especially in some applications.
In safety-critical domains such as autonomous driving, healthcare, and finance, small labeling inconsistencies can cascade into real-world risks. What starts as a data issue can surface as misread road scenes, incorrect clinical signals, or flawed risk decisions.
Why label ownership erodes as teams grow
Most annotation workflows are designed to move work forward, not preserve decisions.
They capture what was labeled and who labeled it. They often record the review status. What they don’t reliably store is the reasoning behind labeling decisions.
- Why was an object included in one case but excluded in another?
- How were disagreements resolved?
- Which interpretation should be reused the next time a similar case appears?
In the early stages, people remember these answers. As teams grow, people change. Context is lost. Decisions are rediscovered—or worse, contradicted. Ownership erodes not because teams stop caring, but because the system doesn’t help them remember. At scale, label consistency cannot rely on institutional memory. It must be enforced by design.
Widely used datasets like COCO illustrate how labeling decisions made for convenience—such as grouping many similar objects under a single “crowd” annotation—can obscure individual instances and weaken long-term label consistency at scale

Common fixes that don’t hold up
When inconsistency becomes visible, teams typically respond in familiar ways.
- They add more reviewers.
- They increase QA sampling.
- They outsource annotation to external vendors.
- They lean harder on automation.
Each of these helps in the short term, and each eventually fails.
Manual review doesn’t scale without becoming a bottleneck. Sampling inevitably misses rare but critical edge cases. Outsourcing often hides decision-making behind process layers. Automation, when applied without strong constraints, simply accelerates inconsistent behavior.
These approaches are reactive. They focus on catching errors after labels are created rather than preventing inconsistency from entering the pipeline in the first place.
At scale, a review alone cannot guarantee consistency. It can only slow down its failure.
What “label consistency” means in production
For teams operating real-world AI systems, label consistency is not about perfection but reliability over time.
Consistent labels mean that:
- Definitions are explicit, not assumed
- Ambiguity surfaces early
- Similar cases are handled in similar ways
- Decisions made once can be reused again
In other words, consistency exists when the system makes it difficult to label the same thing differently tomorrow than it was labeled today.
This is a crucial shift in thinking. Data Quality is no longer something that happens at the end of the pipeline. It becomes a property of the workflow itself.
Annotation systems that scale successfully don’t just produce labels faster; they also enable more efficient labeling. They encode structure—rules, constraints, and checks that preserve meaning as volume grows.

What breaks first when consistency isn’t protected
When consistency is not enforced, problems appear gradually and compound quietly.
Models trained on inconsistent labels become unstable. Retraining yields diminishing returns or unexpected regressions. Different teams working with similar data produce conflicting results. Reviews become debates rather than confirmations.
Perhaps most costly, trust erodes. Teams begin to question whether outcomes reflect reality or artifacts of labeling drift. Debugging shifts from models to data, and progress slows.
These failures are hard to diagnose because they don’t point to a single bad label or annotator. They emerge from systems that allow inconsistency to accumulate unchecked.
At that point, fixing the problem often means revisiting large portions of the dataset—sometimes after models are already in production.
How high-performing teams design annotation pipelines
Teams that scale annotation without losing consistency approach the problem differently.
They accept that disagreement is inevitable and design systems that surface it early. Instead of reviewing everything, they focus human attention where uncertainty exists. Instead of assuming correctness, they measure it.
One of the most effective techniques here is multi-annotator validation.
Put simply, it refers to assigning the same data to multiple annotators and comparing the results automatically. When annotations agree, confidence increases. When they don’t, the system flags the disagreement immediately.
This approach shifts quality assurance from after-the-fact inspection to real-time validation. Reviewers no longer spend time checking every label. They focus only on cases that actually need judgment.
Crucially, this makes quality scalable. As volume grows, the system continues to highlight ambiguity instead of letting it slip through.

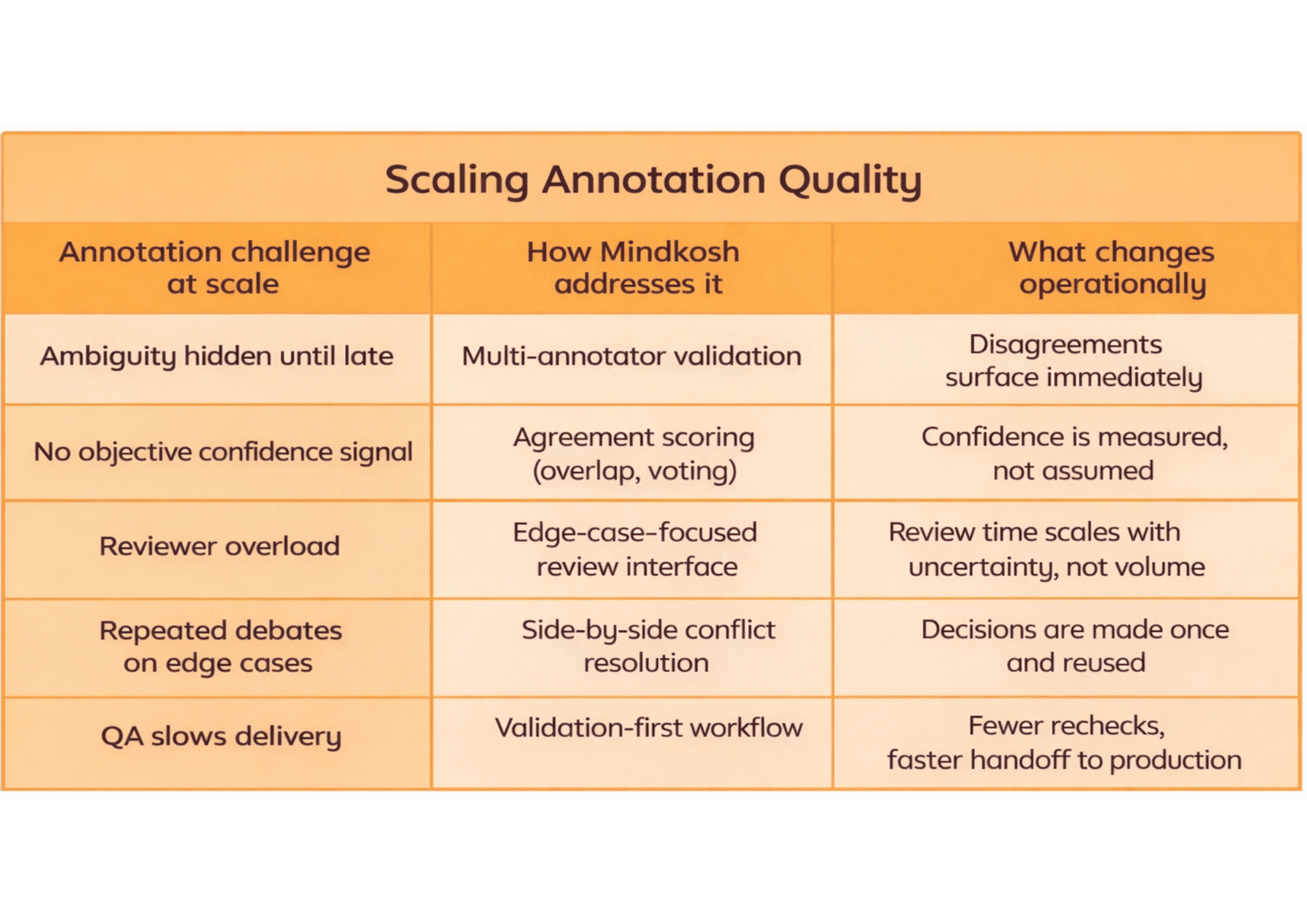
A closer look at Mindkosh
Mindkosh is built around a QA-first approach to annotation, where consistency checks are embedded directly into the workflow rather than added as a downstream review step.
- Multi-annotator validation surfaces ambiguity by having the same data labeled by multiple annotators upfront.
- Agreement scoring (such as majority voting and overlap) replaces guesswork with measurable confidence, clearly showing where human judgment is needed.
- Edge-case–focused review workflows ensure reviewers spend time resolving uncertainty instead of rechecking obvious labels.
- Context-aware conflict resolution allows disagreements to be resolved once and applied consistently across the dataset.
Together, these capabilities prevent silent drift and ensure annotation pipelines scale without becoming fragile.
A practical self-check
For anyone responsible for annotation quality, a few questions can quickly reveal whether a pipeline is built to scale:
- Can labeling decisions made today be explained months later?
- Do new annotators automatically inherit existing interpretations?
- Are inconsistencies detected during annotation, or only after models fail?
- Does increasing volume increase confidence—or anxiety?
If these questions are difficult to answer, the issue is unlikely to be individual performance. It’s more often the absence of a system designed to preserve consistency.
Scale doesn’t break consistency—systems do
Scaling annotation pipelines is unavoidable for teams building real-world AI systems. Losing label consistency doesn’t have to be.
The difference lies in whether quality is treated as a review problem or a workflow problem. Teams that succeed at scale design annotation systems that surface ambiguity early, preserve decisions over time, and make inconsistency difficult by default.
If you’re evaluating how your current setup will perform as volume and complexity increase, now is the right time to assess whether it enforces consistency—or simply hopes for it.
And if you’re looking to reduce review effort while increasing confidence in your labels, Mindkosh is built to help teams do exactly that.



