
Introduction: Vision is the brain of the robot
Imagine a world where robots assist in surgery, navigate busy warehouses, and even interact socially with humans—all without skipping a beat. This is no longer science fiction; it’s rapidly becoming reality, thanks to the intersection of robotics and computer vision.
Computer vision gives machines the ability to “see,” but it’s not magic—it’s mathematics, data, and most importantly, annotation. Every action a robot takes in a dynamic real-world environment starts with accurate perception. And that perception is built on the foundation of well-labeled data.
Without annotated data, computer vision is blind. A surgical robot doesn’t know where to cut. A warehouse robot doesn’t know how to find aisle 3. An autonomous vehicle doesn’t know what a stop sign looks like. Annotation transforms chaotic, unstructured visual data into structured intelligence that robotic systems can learn from and act on.
In this blog, we explore how data annotation fuels robotic perception across industries—from navigation and manufacturing to healthcare and human interaction. Whether you’re building a surgical assistant or a warehouse automation bot, understanding the pivotal role of annotation in robotic vision is essential.

Role of data annotation in robotic vision
Why robots need labeled data
At the core of any robotic vision system is a set of machine learning models trained on annotated data. This data consists of images, videos, and 3D sensor outputs (such as LiDAR point clouds), where each frame is labeled with information that a robot must recognize and understand.
Let’s consider the types of tasks that annotated data supports:
- Object Detection: Enables robots to recognize and localize tools, products, or people.
- Semantic Segmentation: Provides pixel-level understanding of environments.
- Instance Segmentation: Helps distinguish between different instances of similar objects (e.g., several screws of the same type).
- Pose Estimation: Allows understanding of the spatial orientation of objects, humans, or other robots.
- Depth and Range Estimation: Often derived from annotated stereo images or point clouds for spatial reasoning.
These annotations train neural networks that serve as the "eyes" of a robot. A warehouse robot, for example, may receive input from four cameras and two LiDAR units—combined, these provide rich sensory data that is useless until it is labeled for training.
Common annotation techniques in robotics
Let’s explore the core annotation types more deeply, including when and how they are used in real-world robotic systems.
Bounding box annotation
The bound box annotation technique involves drawing rectangular boxes around objects of interest.
Ideal for:
- Warehouse robotics (identifying boxes, packages)
- Security robots (detecting intruders or anomalies)
- Basic object detection tasks
Benefits:
- Fast and cost-efficient to label
- Works well for large, well-separated objects
- Good baseline for object detection models
Limitation:
- Doesn’t capture object shape accurately, leading to possible background noise in training data.
- Limited effectiveness in cluttered or irregular environments
Polygon annotation
Polygon annotation makes use of polygons to allow for accurate tracing of object boundaries—essential for irregular or complex shapes.
Ideal for:
- Identifying curved robotic arms, mechanical parts
- Mapping road boundaries for autonomous vehicles
- Detecting deformable objects like wires or cables
Benefits:
- Improved model performance in cluttered or complex scenes
- Higher precision, for instance, in segmentation tasks
Limitations:
- Slower and more labor-intensive than boxes
- Requires skilled annotators for consistent outlines
- Can become inconsistent across large datasets without QA
Keypoint & skeleton annotation
In keypoint and skeleton annotation, keypoints mark critical parts of a structure. In human pose estimation, they include joints like elbows and knees. In robotic arms, they map the positions of the actuators.
Ideal for:
- Human-robot interaction (understanding gestures, body language)
- Industrial robotics (monitoring manipulator motion)
- Sports analytics and physical therapy (Robotic arm calibration and movement analysis)
Benefits:
- Captures fine-grained motion and articulation
- Essential for tracking humans safely in shared workspaces
- Enables predictive movement modeling
Limitations:
- Harder to annotate accurately, especially in occlusions
- Requires strict style guides to avoid label drift
- Sensitive to camera angle and lighting variability
Semantic segmentation
Semantic segmentation is where every pixel is assigned a class, enabling robots to understand scenes holistically.
Ideal for:
- Autonomous driving
- Indoor mapping
- Agricultural robotics (distinguishing crops from weeds)
Benefits:
- Provides global scene context
- Supports precise planning and navigation tasks
- Reduces ambiguity around object boundaries
Limitations:
- Extremely time-consuming to annotate manually
- Requires significant computing for training
- Errors in a few pixels can degrade overall model outcomes
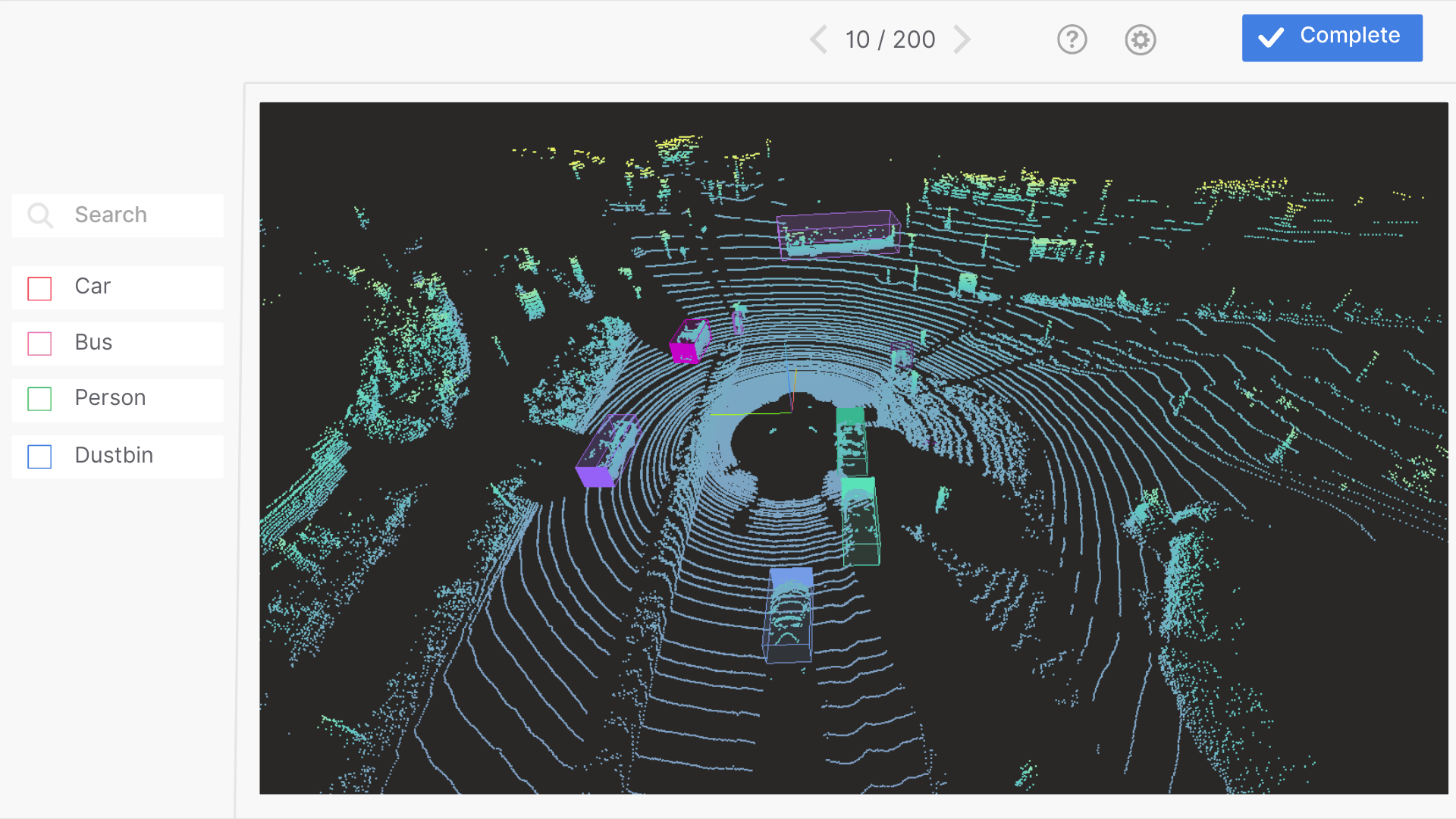
3D Point Cloud annotation
3D point cloud annotation is where LiDAR sensors generate millions of data points per second. Annotating these point clouds helps robots detect objects in 3D space.
Ideal for:
- Delivery robots navigating crowded sidewalks
- Construction bots analyzing terrain
- Self-driving cars interpreting traffic scenes
Benefits:
- True 3D understanding of the environment
- Works in low-light or nighttime conditions where RGB fails
- Accurate distance, depth, and shape reasoning
Limitations:
- Requires specialized tools and trained annotators
- Sparse or noisy LiDAR data makes labeling challenging
- Multi-sensor fusion (RGB + LiDAR) increases complexity

Applications of annotation-driven computer vision in robotics
Autonomous navigation
Robots that move—on wheels, legs, or tracks—rely on annotated data to avoid collisions, follow paths, and make intelligent decisions.
Annotations required:
- Lane lines
- Curbs and sidewalks665
- Pedestrian zones
- Road signs and traffic lights
Example:
- An autonomous floor-cleaning robot uses semantic segmentation to distinguish dirty vs. clean areas and avoid humans.
- In warehouses, robots use annotated 3D maps and object detections to locate inventory, avoid obstacles, and find the most efficient path.
Human-Robot Interaction (HRI)
Natural human-robot collaboration requires machines to understand social signals. That means visual recognition of gestures, expressions, and body movements.
Annotation needs:
- Pose keypoints (hands, arms, legs)
- Emotion labels ( simple emotions like happy or sad)
- Gesture recognition
Example:
- Robots assisting elderly users by detecting distress
- Hospitality robots recognizing a raised hand as a call for attention
- Industrial cobots adjust speed based on a human's proximity
These systems depend heavily on consistent, high-quality annotations to avoid misinterpretation that could lead to safety risks.
Medical & surgical robotics
In high-stakes environments like the operating room, precision in perception is paramount. Annotated medical images help robots:
- Segment tissues and organs
- Identify surgical tools
- Track the progression of procedures in real time
Example:
- A robotic-assisted surgery system that recognizes anatomical features from a 3D scan and aligns its incisions accordingly.
Annotation forms used:
- 3D voxel segmentation
- Annotated keypoints for instrument tip tracking
- Motion prediction based on prior scans
High-quality annotation can directly affect procedural accuracy.
Key challenges in annotation for robotics
Real-time data and dynamic environments
Robotics environments are dynamic. Objects move. People walk through the frame. Lighting changes. Annotation needs to keep pace.
Challenges:
- Annotating video at 30+ fps
- Synchronizing multi-sensor inputs
- Maintaining time-series consistency
Solutions:
- Frame interpolation
- Auto-labeling with manual verification
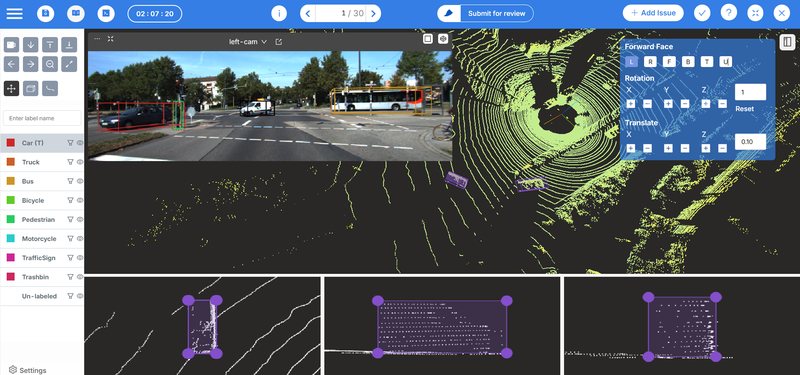
- Streaming annotation interfaces (e.g., Mindkosh)
Mindkosh’s streaming annotation interface lets teams label high-framerate video and sensor fusion data efficiently, without breaking temporal consistency.
Label consistency across sequences
When training with video sequences or continuous sensor data, inconsistencies between frames degrade performance.
Example problem:
- Annotator A labels a screwdriver as "tool."
- Annotator B later labels it "hardware."
Result: the robot gets confused.
Best practices:
- Use consensus tools
- QA workflows with expert reviewers
- Annotation style guides
Temporal coherence is essential in robotic motion planning. Platforms like Mindkosh help manage large annotation teams and ensure standardization across massive datasets.
Sensor fusion labeling
Robots use a variety of sensors: RGB cameras, thermal imaging, LiDAR, radar, sonar, and depth cameras. Each sensor offers a different view of reality.
Fusion means:
- Annotating aligned data from multiple sources
- Maintaining temporal and spatial synchronization
Example:
- Self-driving car that combines LiDAR point clouds and RGB video to detect pedestrians even in poor light.
Mindkosh supports synchronized annotation across LiDAR, RGB, radar, and depth sensors, maintaining spatial and temporal alignment — a requirement for any serious robotics team. Especially in the autonomous vehicles use case.
Real-world case studies
Case study 1: Ocado’s warehouse bots
British grocery giant Ocado uses autonomous robots to fetch items from a warehouse grid. These bots rely on annotated data to identify:
- Bin locations
- Inventory types
- Human worker proximity
Impact: Implementing pose-estimation and zone-labeling annotations led to significant gains across Ocado’s fulfillment operations. The improvements boosted productivity and sped up picking, packing, and overall order throughput — with teams achieving 73% more lines picked per hour.
Case study 2: Da Vinci Surgical System
This robotic surgical assistant requires pixel-perfect annotations of:
- Anatomical structures
- Blood vessels
- Surgical instruments
By training on millions of labeled frames, it can now assist surgeons with unprecedented precision.
Annotation tool used: Proprietary 3D voxel segmentation with QA reviews by medical experts.
Case study 3: Boston dynamics’ spot
Spot, the four-legged robot, is trained using point cloud and image annotation to walk, avoid obstacles, and climb stairs.
Sensors used:
- 360° RGB cameras
- Stereo vision
- LiDAR
Annotation needs:
- Multi-modal labeling
- Frame-by-frame pose tracking
Future outlook: What’s next for annotated robotics
The next generation of annotation systems will be faster, smarter, and more deeply integrated into AI workflows.
AI-assisted annotation
Using pretrained models to label data that humans only need to correct. Saves up to 70% annotation time.
Examples:
- Detecting warehouse items automatically
- Suggesting bounding boxes for moving objects

Active learning pipelines
Letting robots decide what data they need next. They request new annotations where confidence is low—creating a feedback loop between model and annotator.
Impact:
- Less data needed overall
- Faster time to deployment
Few-shot & zero-shot learning
Imagine training a robot to detect a tool from just three examples. That’s the promise of few-shot learning, enabled by smarter annotations and better generalization.
Future application: Robots in new environments where data is scarce.
Tight collaboration between engineers and annotators
New platforms like Mindkosh are bridging gaps between the ML team and the data team. This leads to:
- More relevant labels
- Quicker iterations
- Better model performance
Conclusion
Robotic perception begins with annotated data. Without it, robots are just hardware. With it, they become intelligent collaborators in surgery, logistics, exploration, and beyond.
From detecting boxes to performing heart surgery, annotated data powers vision—and vision powers action. The smarter our annotation pipelines, the more effective and autonomous our robots become.
Annotation is not a backend task anymore. It's a strategic advantage.
And with platforms like Mindkosh, the future of scalable, accurate, multi-sensor annotation is already here.
So if you’re building the next generation of intelligent robots, start where perception begins—start with annotation.



