In an age where machines can drive cars, diagnose diseases, and create art, it's easy to forget that their ability to "see" is still developing. Our eyes and brains work together seamlessly to understand visual information — distinguishing between objects, identifying scenes, and making sense of our surroundings. But for machines, this process is far more complex.
Enter semantic image segmentation, one of the most vital tasks in computer vision. Unlike basic classification that assigns a label to an entire image or object detection that draws a box around detected items, semantic segmentation goes a step further — it classifies every single pixel in an image. In other words, it teaches machines to not just recognize an object, but to understand what part of the image belongs to it.
Why is this important? Because pixel-level understanding opens doors to highly precise and intelligent systems. Whether it’s an autonomous vehicle identifying a pedestrian on the street, or a radiologist using AI to analyze a tumor in a CT scan, semantic segmentation lies at the heart of it all.
This blog will dive deep into:
- The core concepts of semantic image segmentation
- The key techniques and models powering it
- Real-world applications that make it indispensable
- Challenges still faced by developers and researchers
- The future of segmentation in AI systems
Let’s unravel the layers and understand how machines are learning to see the world — pixel by pixel.

Core concepts
Pixel-level classification: Understanding the foundation
Semantic segmentation add more precision to bounding box object detection. Instead of identifying just the presence of a cat or a car in an image, the algorithm marks exactly which pixels belong to the cat, the car, the background, and so on.
This task requires immense precision and contextual understanding. For instance, distinguishing the pixels of a tree in front of a building or separating overlapping pedestrians in a crowd is no trivial feat. Every pixel must be assigned to a semantic class — sky, road, vehicle, person, animal, etc.
This pixel-wise approach allows for fine-grained scene understanding — a level of detail that’s crucial for applications like surgical AI tools or drone navigation over complex terrains.
Segmentation algorithms: From rule-based to deep learning
Initially, segmentation was tackled using handcrafted features — edge detectors, color histograms, or texture filters. These rule-based techniques, while useful in constrained environments, struggled with real-world complexity.
The game changed with the rise of deep learning. Specifically, Convolutional Neural Networks (CNNs) enabled automatic feature extraction and better generalization. Today’s semantic segmentation models rely on hierarchical layers of convolution to extract spatial features and generate detailed pixel maps.
Deep learning has turned segmentation into a data-driven discipline — the more diverse and annotated data it sees, the better it performs.
Key techniques and models
Convolutional Neural Networks (CNNs)
CNNs are the building blocks of most semantic segmentation models. Through layers of filters, CNNs capture local patterns — edges, textures, shapes — and combine them to form high-level features.
However, while CNNs are great for classification, they were not originally designed for spatially dense outputs like segmentation maps. This is where new architectures came into play.
Encoder-decoder architectures
To translate the compact, abstract features learned by CNNs into detailed segmentation maps, researchers developed encoder-decoder frameworks.
- The encoder (usually a CNN) compresses the input image into a low-dimensional representation.
- The decoder then upsamples this representation back to the original size, producing a segmented output where each pixel is classified.
One of the most popular models, U-Net, uses this strategy and adds skip connections to preserve spatial information lost during encoding. It has been widely adopted in medical imaging for its ability to produce highly accurate segmentations even with limited data.
Skip connections: Preserving the details
Imagine painting a highly detailed picture from a rough sketch — you’d want to refer back to the original image repeatedly. That’s exactly what skip connections do.
They allow the decoder to access low-level features from the encoder, helping the model maintain both context and detail. This fusion significantly improves segmentation quality, especially in scenarios where edge sharpness is critical, such as tumor detection or road boundaries in autonomous driving.
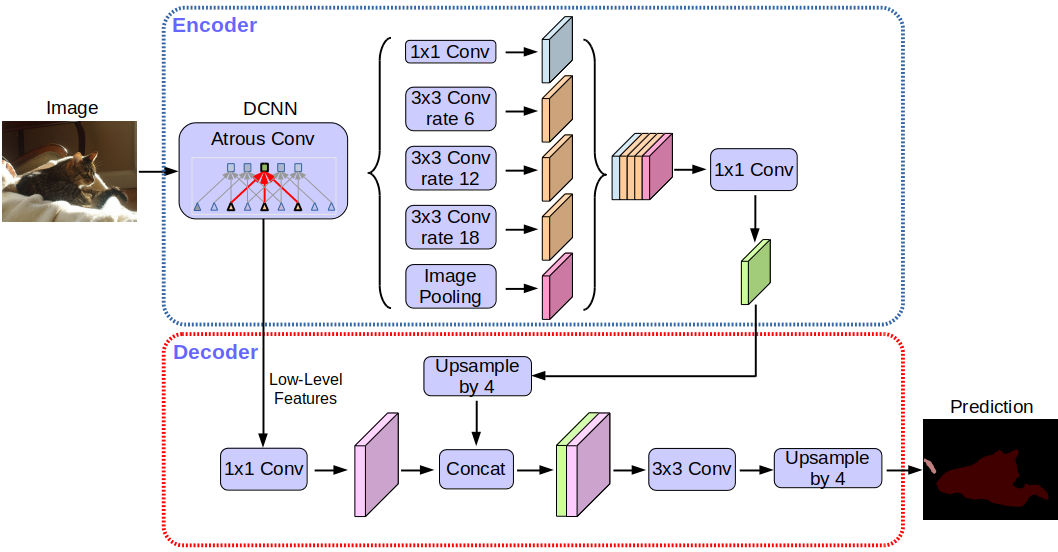
Dilated convolutions and Atrous Spatial Pyramid Pooling (ASPP)
Advanced segmentation models like DeepLab use techniques such as dilated convolutions, which expand the field of view without losing resolution. Combined with ASPP, these techniques allow models to capture multi-scale context — understanding both the fine details and the broader structure of an image.
For deeper insight into segmentation at scale, check out The best Image Segmentation tools in 2024.
Challenges and solutions
Semantic segmentation is powerful, but far from perfect. Real-world implementation brings a slew of challenges.
Low resolution and diverse image sources
Images captured by drones, surveillance cameras, or medical equipment often suffer from low resolution, varied lighting, or distortions.
To combat this:
- Data augmentation is used to artificially diversify training datasets.
- Transfer learning allows models trained on one domain (e.g., urban landscapes) to adapt to another (e.g., indoor scenes).
- Super-resolution techniques are being applied to improve input quality before segmentation.
Class imbalance and small objects
In many datasets, some classes (like roads or buildings) dominate, while others (like pedestrians or traffic signs) appear rarely. This imbalance causes models to overfit on the dominant classes.
Solution: Specialized loss functions like dice loss or focal loss penalize misclassification of underrepresented classes more heavily, ensuring better balance.
Noisy or ambiguous boundaries
Boundaries between objects can be unclear — think of a person wearing camo in a forest. Distinguishing foreground from background is a challenge.
Solution: Using attention mechanisms, models can focus on subtle cues to improve boundary segmentation. Also, integrating edge detection modules helps sharpen object boundaries.
Real-time performance for edge devices
High-resolution segmentation is computationally expensive, making it hard to deploy on devices like smartphones or drones.
Solution: Lightweight models like MobileNet or Fast-SCNN are optimized for speed and efficiency, enabling near real-time performance on edge devices.

Applications: Real-world impact
Semantic segmentation is not just a research curiosity — it's transforming industries.
Autonomous vehicles
Self-driving cars rely heavily on semantic segmentation to:
- Identify drivable lanes
- Recognize traffic signs, signals, and pedestrians
- Understand complex urban environments
It helps the car “see” the world with human-like precision, enabling safer navigation and decision-making.
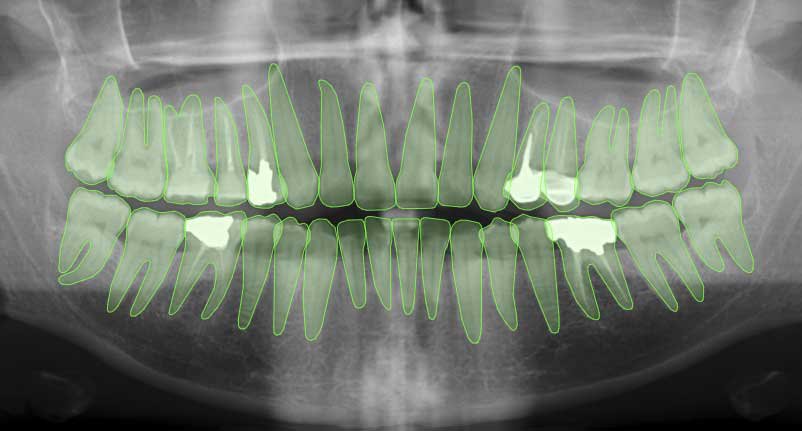
Medical imaging
Doctors now use AI tools powered by segmentation to:
- Detect tumors, lesions, or abnormalities in X-rays, MRIs, or CT scans
- Plan surgeries with detailed anatomical maps
- Speed up diagnosis while improving accuracy
In diseases like cancer, where millimeters can make a difference, pixel-precise segmentation is a game changer.
Agriculture and environment
From analyzing crop health via satellite images to tracking deforestation or water levels, semantic segmentation helps in:
- Classifying land cover types
- Monitoring ecosystem changes
- Managing natural resources more efficiently
Augmented reality and gaming
AR apps and games use segmentation to separate foreground from background in real time, enabling immersive experiences. Think of Snapchat filters or video conferencing apps that blur your background — all powered by real-time segmentation.
Future directions
The field of semantic segmentation continues to evolve rapidly. Here's what the future holds:
Self-supervised and unsupervised learning
Manually annotating pixel-level labels is time-consuming and expensive. Future models aim to learn without extensive labeled data, using techniques like self-supervised learning, where the model teaches itself by predicting missing parts of the image.
Multimodal segmentation
Combining image data with other modalities like depth (from LiDAR), thermal imaging, or even textual descriptions allows for richer segmentation.
For example, in autonomous vehicles, integrating LiDAR point clouds with semantic segmentation provides more accurate scene understanding.
3D and video segmentation
Moving from static images to video segmentation allows for temporal consistency — tracking objects over time.
In 3D segmentation, models classify points in a 3D space, enabling applications in robotics, architecture, and AR/VR.
Human-in-the-loop systems
In scenarios like medical diagnosis or satellite monitoring, human-AI collaboration is crucial. Systems that allow humans to review and correct segmentations improve both accuracy and trust. Read Looking out for the human in AI & Data Annotation.
Conclusion
Semantic image segmentation represents a powerful leap in how machines interpret visual data. By assigning meaning to every pixel, it bridges the gap between raw perception and intelligent understanding.
Whether it’s navigating roads, saving lives, protecting forests, or enhancing our digital experiences, semantic segmentation is the invisible engine driving innovation in AI and computer vision.
Yet, this is just the beginning. As research pushes boundaries and models become more efficient, adaptable, and context-aware, the future of semantic segmentation looks brighter than ever. Machines won’t just recognize images — they’ll understand them in vivid, human-like detail.
We’re entering an era where pixels are more than just colors. They’re the building blocks of machine intelligence — and semantic segmentation is teaching AI how to read them.




