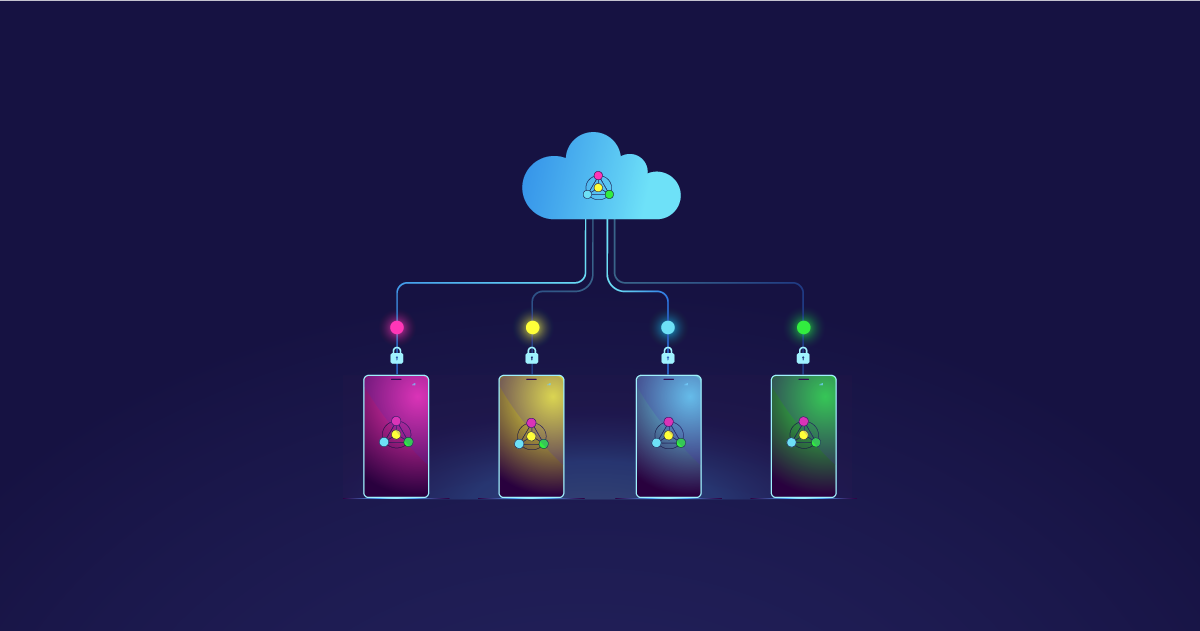
Introduced in 2016 by Google through first a short blog post, and then through their now seminal paper, Federated Learning has gone from strength to strength in the years since.
Federated learning is a way to train machine learning models collaboratively, but without ever sharing the individual data points themselves. In a more general sense, FL allows for machine learning algorithms to gain experience from a broad range of data sets located at different locations. The approach enables multiple organizations to collaborate on the development of models, exposing the model to a significantly wider range of data than what any single organization possesses in-house. This is particularly useful in situations where:
- Privacy is a major concern: Data can be sensitive, specially in industries like Medical and Finance. Federated learning allows models to be trained on this data without ever leaving the device or server where it's stored.
- Data is geographically distributed: Imagine training a model for a global company with offices and users all over the world. Federated learning allows models to be trained on local data while still contributing to a central, improved model.
How does Federated learning work?
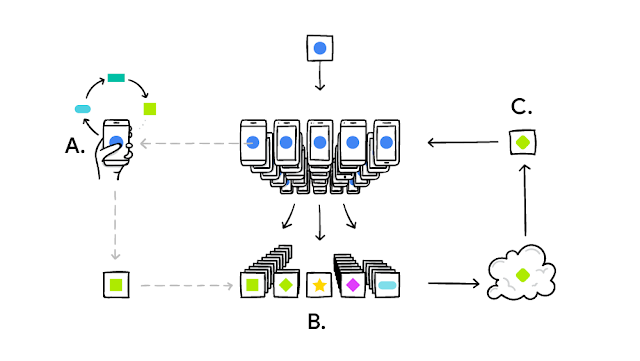
Here's how federated learning works:
- A central server distributes a base machine learning model to participating devices (phones, laptops, etc.).
- Each device trains the model locally on its own private data. This training process only updates the model's internal parameters, not the actual data.
- The devices send their updated model parameters back to the central server, essentially summarizing what they learned from their local data.
- The central server aggregates these updates from all devices, combining the knowledge gained from everyone's data.
- The central server creates an improved, global model based on the aggregated updates.
- The improved model is then sent back to the devices for further training in the next round.
Difference between federated learning and traditional forms of Machine Learning training
Traditional Machine Learning involves a data pipeline that uses a central server (on-premises or on the cloud) that hosts the trained ML model in order to make predictions. The downside of this architecture is that all the data collected by local devices and sensors is sent back to the central server for processing, and subsequently returned back to the devices. This round-trip limits a model's ability to learn in real-time.
Federated learning (FL) in contrast, is an approach that downloads the current model and computes an updated model on the device itself (a little like edge computing) using local data. Updates from these locally trained models are then sent from the devices back to the central server where they are aggregated. Essentially, weights are averaged and then a single consolidated and improved global model is sent back to the devices.
Why is this such a big deal?
Because one, it makes the learning distributed, so that multiple organizations can collaborate on the learning. And two, it allows this distribution while making sure that the actual data is never shared across devices. Only the updates are. Which is a big deal if you care about privacy.
There are many other benefits:
It enables devices to learn collaboratively
Federated learning allows models to learn a shared prediction model while keeping the training data on the device instead of requiring the data to be uploaded and stored on a central server.
It moves model training to the edge
Namely devices such as smartphones, tablets, IoT, or even organizations like hospitals that are required to operate under strict privacy constraints. Having personal data remain local is a strong security benefit.
It makes real-time prediction possible
In the Federated learning paradigm, prediction is done on the device itself. This reduces the time lag that occurs due to transmitting raw data back to a central server and then shipping the results back to the device. Since the models reside on the device, the prediction process works even when there is no Internet connectivity.
It reduces the amount of hardware infrastructure required.
Federated learning uses minimal hardware and what is available on mobile devices is more than enough to run FL models.
It is evident that the idea holds a lot of promise. However, it does face some big challenges:
- FL networks have to be able to tolerate variability in hardware that affects storage, computational, and communication capabilities of each device in a federated network.
- Communicating model updates throughout the training process can still reveal sensitive information, either to a third party, or to the central server.
- Data across devices can vary greatly in their format as well as content, potentially impacting model performance.
The Federated Learning community is hard at work trying to solve these issues. If you are still not convinced this is big, checkout this super cool manga depiction of the idea from Google.