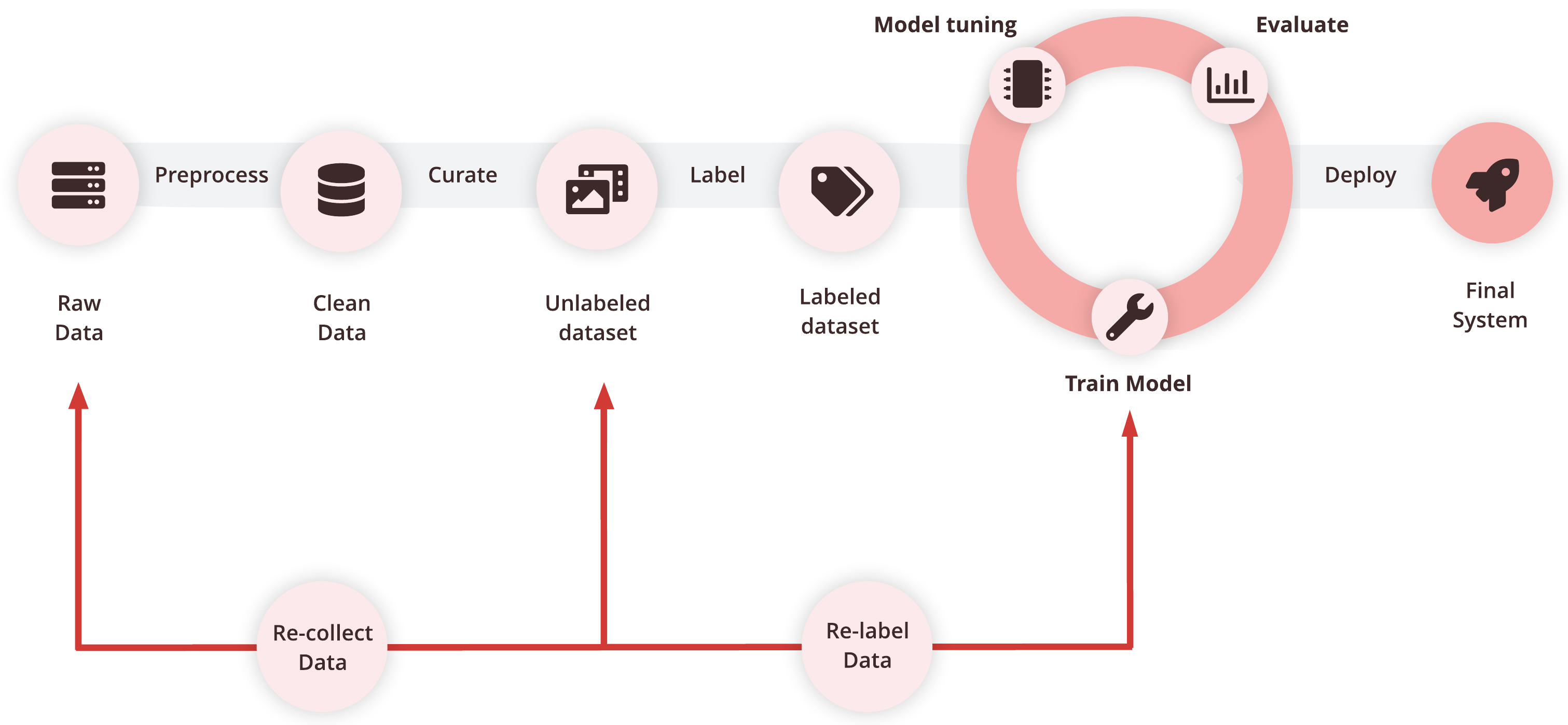
The Data Centric approach to building Machine Learning systems focuses on data instead of code. Traditionally, ML system development involves a Model cycle - continuous testing and adaption of models while keeping the data static. The Data centric approach adds a Data cycle to the process - continuous improvement of Data Quality.
Why should I care about Data Centric Machine Learning ?
Because creating an AI/ML system in a lab is completely different from creating one that works in the real world, close to 90% of AI systems companies work on, are never brought to light. To a large extent, this can be attributed to the fact that real world data can differ significantly from the data in the lab.
Current Machine learning architectures are highly evolved for identifying photographs, recognizing speech, generating text etc. Tinkering with their architecture is perhaps not the best way to improve them anymore. This is where Data Centric ML comes in.
In practical terms, what does Data Centric ML entail?
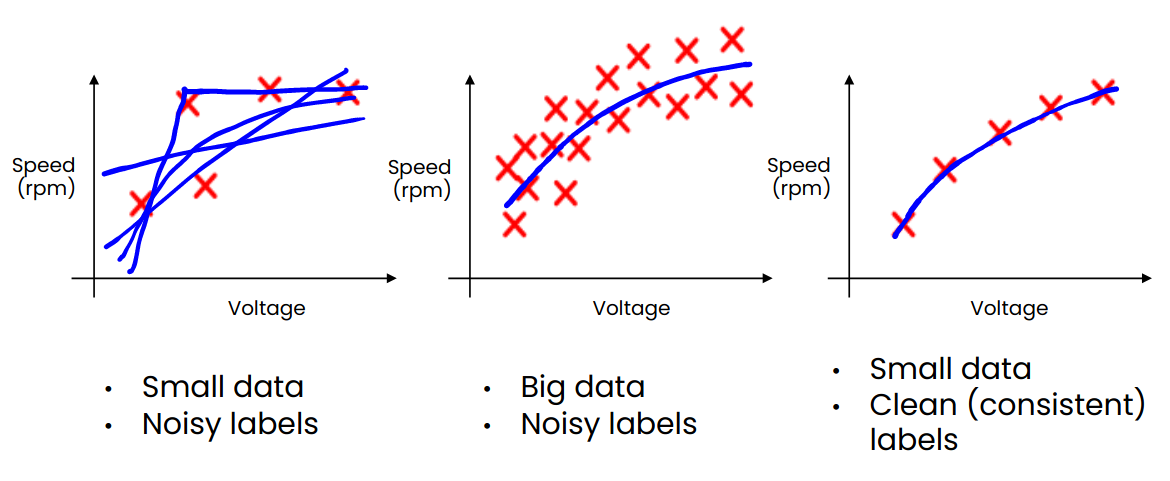
Data volume and curation
The amount of training data your system is trained on is very important. Moreover, if your dataset is small, data quality matters much more than if your dataset is large. Having a large dataset can often mask the problems your data might have. But the approach of blindly amassing more data can be very inefficient and costly.
So we need to look at our model performance carefully and decide what kind of data is required to improve our model. Perhaps we need to include more images in snowy conditions? Or we could do with more images at night. Data curation is a very crucial step when preparing training data.
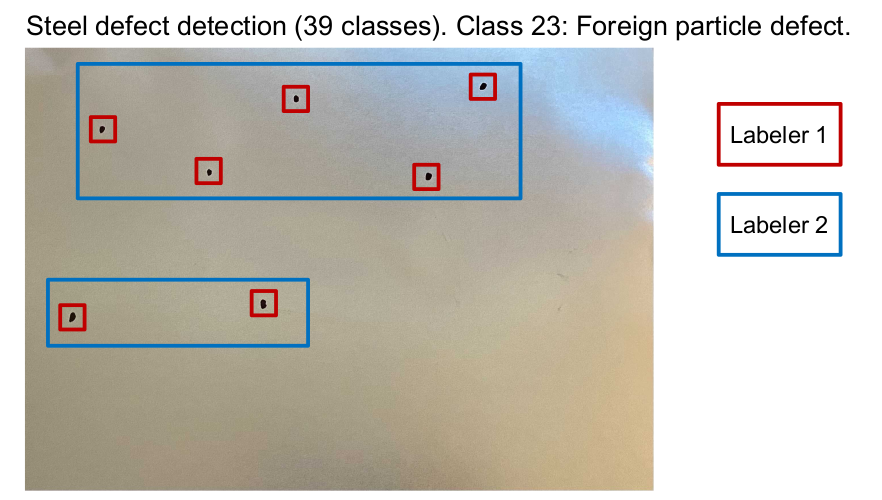
Data consistency
Consistency in data annotation is very important, because any inconsistency can derail the model and also make your evaluation unreliable. In our own experience here at Mindkosh AI, we believe focusing on the following points can help your data labels stay consistent.
- Annotate a small sample of dataset yourself before formulating instructions for your labeling team. This way you can get a better idea of the possible errors an annotator can make.
- Measure the quality of your annotated data. There are two ways in which you can do this:
- Review a random batch of annotated data to make sure everything is as expected.
- Before sending your data for annotation, label a small portion of the data yourself, and include this in the data you send for annotation. Once the entire data is labeled, you can compare your labels with the ones your labeling team annotated. This technique is called Honeypot.
- If you keep finding inconsistencies even with these techniques, it can be helpful to get your data annotated by multiple labelers and use majority vote as the final ground truth label.
Data quality
As mentioned earlier, if your dataset is small, data quality matters much more. Noisy labels have a much more severe effect on your model performance if you have only 1000 images versus if you have 10,000 images. How can you make sure your labels are clean and high quality?
Make sure that:
- Your data is be defined consistently. That is the definition of your labels is unambiguous.
- Your data covers all important cases you expect to see in the real world.
- Your data is updated timely. If anything in the real world changes, your training data should be updated to reflect those changes.
Measuring data quality is another crucial step in maintaining high quality across a dataset. This can be tricky when labeling raw data, as you don't usually have ground truth data to compare the labels against. Here we describe some commonly used methods to measure data quality both quantitatively as well as qualitatively.
How can I get started with Data Centric ML?
While the tips mentioned above should be enough to get you started on your journey to Data centric ML, they are by no means comprehensive. If you want to know more, you can go through this list of research papers in the field we have compiled for you.
You can also checkout our list of open-source tools that can be incredibly helpful to get started.
As always, the best way to learn something new is to talk with the fellow members of the community. You can join our community on Reddit, or if you are active on linkedin you can join our linkedin group as well.
Happy journey!