
When teams adopt AI-assisted annotation, the promise is straightforward: faster labeling, lower QA overhead, fewer repetitive review cycles. The technology handles the obvious cases. Humans focus on the edge cases. Throughput scales without proportionally scaling headcount.
That's the version on the slide deck.
In practice, many teams find something different. A few months in, QA workload hasn't shrunk — it's grown. Reviewers are still validating the majority of labels. Throughput gains that looked real in pilots start to plateau. And every time the dataset volume increases, the review team scrambles to keep pace.
None of this is a failure of AI adoption. Most of the time, it's a signal of something more specific: workflow architecture that was never properly designed to be scalable.
QA, validation rounds, and rework cycles can add 20–50% to base annotation costs — and that's before factoring in the coordination overhead and relabeling costs that most teams only discover mid-project. When annotations require rework, the labor cost for affected data effectively doubles, and budget projections rarely survive contact with scale.
The uncomfortable truth is that a pipeline can look AI-assisted on paper while operating almost entirely manually beneath the surface. The scale of that gap between AI's promise and its operational reality isn't anecdotal — BCG's 2025 research makes it concrete.
This article is built for annotation teams who suspect their workflow has this problem but haven't had a precise framework to diagnose it. Each sign below is a window into a specific operational weakness. The goal is to help you see where the real friction is entering your pipeline, so you can address the architecture rather than just adding more reviewers.
What healthy AI-assisted annotation workflows actually look like
Before diagnosing problems, it helps to be clear about what a mature pipeline actually does — because the benchmark matters for recognizing when you've drifted from it.
AI assistance should reduce unnecessary review — not eliminate humans entirely
A common misconception is that mature AI-assisted annotation workflows are heading toward full automation. They're not. Human review remains essential, particularly for ambiguous cases and high-stakes labels.
The goal isn't to remove humans from the loop. It's to stop deploying humans on work where their judgment adds little or no value. Reviewing a high-confidence, clearly correct bounding box for the hundredth time isn't quality work — it's rote validation. Mature pipelines are designed to route that kind of work away from human reviewers so their time is concentrated on decisions that actually require judgment.
Over time, a well-functioning AI-assisted workflow should become more efficient, not less. The model improves. Reviewers spend their time where disagreement is meaningful and decisions are consequential. QA coverage becomes increasingly targeted rather than uniformly applied.
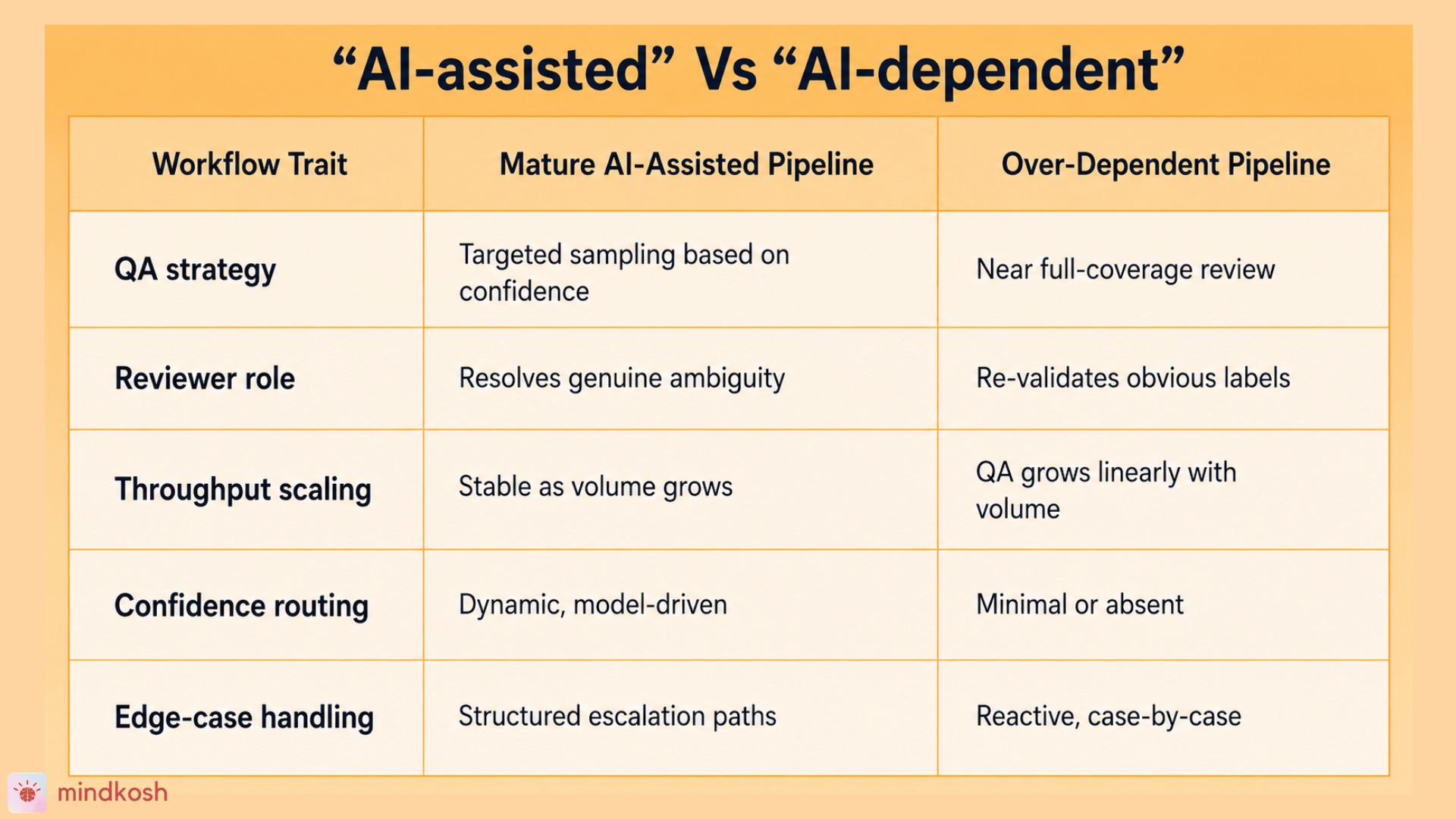
The difference between "AI-assisted" and "AI-dependent" workflows
There's a meaningful distinction between using AI as a workflow accelerator versus depending on AI output while still manually validating nearly everything it produces.
If your workflow still behaves like a manual operation at scale — if QA headcount tracks dataset volume, if reviewers spend most of their time on labels that aren't actually uncertain — these are usually the early warning signs.
Sign #1 — Your team manually reviews nearly every label anyway
This is the most direct signal, and it tends to be the one teams rationalize the longest.
When a team reviews 80–100% of AI-generated labels as a matter of policy, the AI is functioning more like a first-pass suggester than a genuine accelerator. The throughput gains from AI generation are almost entirely consumed by the downstream review burden.
Why this usually signals weak confidence calibration
The reason blanket review policies emerge is almost always the same: the team doesn't trust the model's predictions operationally. That distrust isn't irrational — it usually reflects real experience with mislabeled outputs. But the response — review everything — treats the symptom rather than the cause.
In a well-calibrated system, confidence scores are meaningful. A label predicted with 97% confidence behaves differently from one predicted at 62%. The workflow routes them differently. High-confidence predictions with consistent patterns move through with light-touch sampling. Low-confidence predictions, novel inputs, and class-boundary cases go to reviewers.
When confidence scoring is absent, poorly tuned, or simply not trusted, teams default to blanket coverage. That's a calibration problem — not a reason to review everything indefinitely.
The hidden cost of "safety reviewing"
The instinct to review everything feels conservative and responsible. Operationally, it's expensive in ways that accumulate fast.
Reviewer fatigue increases as repetitive validation work dominates schedules. Labor costs expand without proportional quality improvement, since the majority of those reviews confirm correct labels. Iteration cycles slow down because the QA queue becomes a bottleneck. And the throughput gains that justified the AI investment in the
Sign #2 — QA workload increases every time dataset volume grows
In a genuinely scalable annotation workflow, adding more data shouldn't require adding proportionally more QA capacity. If it does, the pipeline isn't scaling — it's just getting bigger.
Healthy pipelines should scale more efficiently over time
Scaling efficiency in annotation works similarly to any operational system: as volume increases, the infrastructure should absorb it without a linear expansion of manual effort. Models improve on familiar data distributions. Reviewers develop sharper pattern recognition for their domain. Feedback loops tighten. The proportion of labels requiring human intervention should gradually decline, or at a minimum stabilize, even as absolute volume grows.
When that doesn't happen — when every jump in dataset size triggers a parallel expansion of the review team — it's a sign that the workflow lacks the structural mechanisms to absorb scale.
Why linear QA growth becomes operationally dangerous
The downstream consequences accumulate quickly. Annotation teams become hiring-constrained because throughput is gated by reviewer capacity rather than computational infrastructure. Costs rise unpredictably, making it difficult to budget annotation into ML project timelines with any confidence. Delivery timelines slip under volume pressure. And operational complexity compounds as larger review teams introduce their own coordination overhead and inconsistency risks.
It's worth acknowledging that scaling edge cases is genuinely difficult. Even mature annotation operations encounter volume-driven challenges, particularly when data distributions shift or new classes are introduced. No workflow fully eliminates that complexity. But there's a meaningful difference between a workflow that manages scaling pressure through intelligent routing and one that simply adds reviewers as the only available lever.
Sign #3 — Reviewers constantly disagree with each other
Reviewer disagreement is often treated as a personnel or training problem. More often, it's a workflow design problem — and one that AI-assisted labeling can make significantly worse if it's not addressed at the source.
Reviewer disagreement is often a workflow design problem
When multiple reviewers consistently reach different conclusions on similar labels, the root cause is almost never that individual reviewers are careless. It's that the ontology — the set of definitions, rules, and examples that govern how labels are applied — is either unclear, incomplete, or not being applied consistently.
In AI-assisted pipelines, this matters more than in fully manual ones. AI models trained on ambiguous or inconsistently labeled data will propagate that ambiguity at scale. If the ontology doesn't clearly define where class A ends and class B begins, the model learns a blurred version of that boundary. Human reviewers working from the same unclear definitions make different judgment calls. The inconsistency multiplies.
The connection to AI-assisted labeling is direct: AI amplifies whatever ontology exists. If the ontology is ambiguous, the AI will produce ambiguous labels with high confidence, and reviewers will disagree about whether to accept or correct them. Fixing reviewer disagreement means fixing ontology — and building the feedback loops that keep it current as the data distribution evolves.
Sign #4 — Your AI-assisted labeling models struggle with edge cases repeatedly
Every annotation workflow encounters edge cases. The difference between a mature pipeline and a fragile one isn't the absence of edge cases — it's whether edge cases are handled through a structured system or addressed reactively every time they appear.
Edge cases are where annotation systems either mature or break
In a well-functioning workflow, edge cases are anticipated, documented, and routed appropriately. When a novel input falls outside the model's confident prediction zone, it follows a defined path: flagged, escalated to the right reviewer, resolved with a documented decision, and — critically — used to update the ontology or retrain the model so the same case doesn't become a recurring interruption.
In a reactive workflow, edge cases are treated as one-off exceptions. The same inputs reappear in review queues across batches. Reviewers make independent calls without coordination. The model never receives the signal it needs to improve on that category of input. And the operational burden persists indefinitely.
Why repetitive edge-case escalation slows everything down
The compounding effects are significant. Recurring exceptions consume disproportionate reviewer time because they require active judgment rather than quick validation. Low-confidence routing failures — cases where the model should have flagged uncertainty but didn't — surface as downstream errors that require expensive rework. Annotation drift accumulates as different reviewers handle the same edge case differently across batches. Rework loops grow.
The operational signal worth paying attention to is repetition. If the same category of edge case is appearing in escalation queues week after week without any reduction, it suggests that decisions made in review are not making it back into the model or the ontology. That's a feedback loop failure, not just a QA problem.
Segmentation tasks are among the most common sources of edge-case escalation — complex object boundaries, overlapping classes, and ambiguous edges generate disproportionate reviewer disagreement. Mindkosh's magic segment tool addresses this directly, using AI-assisted segmentation to produce precise boundary predictions that reduce manual correction cycles and reviewer load on one of annotation's most time-intensive task types.
Sign #5 — Your reviewers spend more time validating than improving data quality
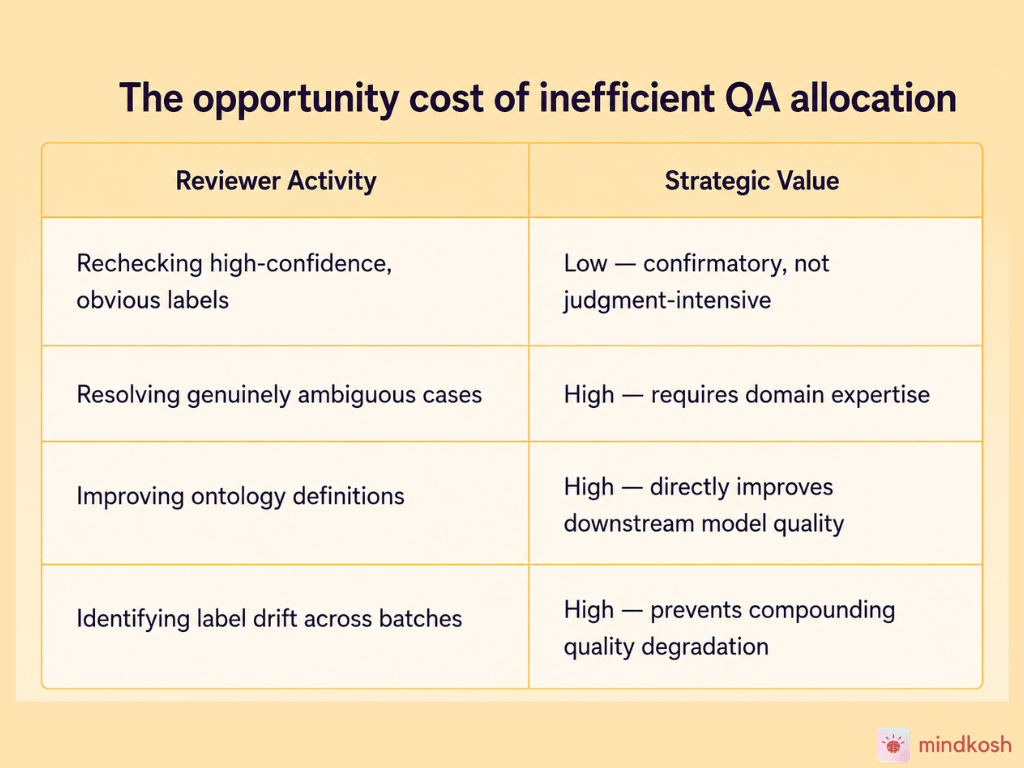
There's a meaningful distinction between reviewers who are validating labels and reviewers who are improving data quality. In many annotation operations, the two activities look similar from the outside but represent very different uses of human expertise.
High-value reviewers should not behave like repetitive validators
Annotation reviewers — particularly experienced domain reviewers — bring judgment that's genuinely scarce. They understand label boundaries, recognize data distribution shifts, identify systematic model errors, and can improve ontology definitions based on what they observe in the data. That expertise has high operational value.
When those same reviewers spend the majority of their time confirming that obvious, high-confidence labels are correct, the expertise is being misallocated. They're functioning as a QA checkbox rather than a quality improvement resource. The work is necessary — but it's not the work that justifies their cost or leverages their capability.
The ROI framing here is straightforward: if 70% of reviewer time is consumed by low-value confirmation work, 70% of your QA labor cost is producing confirmations rather than quality improvements. A better-designed workflow routes the low-value work to sampling or automated checks, and concentrates reviewer time on the decisions that actually require their judgment.
Sign #6 — Annotation rework keeps appearing across batches
Occasional rework is a normal part of any annotation operation. When rework becomes a recurring pattern across multiple batches — particularly when the same label categories or the same types of errors keep reappearing — it signals something more systemic.
Rework is often a sign of weak feedback integration
The function of a review process isn't only to correct individual labels. It's to generate signals that prevent the same errors from recurring. When a reviewer corrects a label, that correction should inform the model, update the ontology if needed, and — where the error reflects a systematic pattern — trigger a broader review of similar items.
When that loop doesn't close, corrections stay local. The model continues producing the same category of error. Reviewers make the same corrections in batch after batch. Rework volume remains stable or grows rather than declining over time.
Why annotation drift compounds over time
Even in teams with strong initial alignment, label quality can drift as conditions change: reviewer interpretations evolve, QA criteria aren't updated to reflect ontology refinements, instructions become stale as new data distributions emerge, and retraining loops are delayed or skipped. Each of these introduces a gradual inconsistency that's often invisible in any single batch but becomes apparent when comparing label quality across a longer time horizon.
It's worth being direct: annotation drift is common even in sophisticated operations. It isn't a sign of incompetence — it's a sign that continuous correction systems weren't built into the workflow from the start. The difference between operations that manage drift and those that don't is rarely about the quality of the reviewers. It's about whether the workflow architecture includes the mechanisms to detect and correct drift before it compounds.
The downstream cost can be substantial. When systematic annotation quality issues are discovered late, teams often face expensive rework cycles involving relabeling, additional QA, and retraining — all of which can significantly increase overall project costs.
Sign #7 — You still cannot confidently predict annotation timelines or QA costs
This sign matters most to operations leaders and procurement stakeholders — and it often surfaces later in the diagnostic process, after the upstream inefficiencies have had time to compound.
Operational unpredictability becomes a business risk
In a well-functioning annotation workflow, project costs and timelines are forecasted with reasonable confidence. QA overhead is predictable within a narrow range because it's determined by workflow rules — confidence thresholds, sampling rates, escalation criteria — rather than by how many unexpected problems emerge during review.
When QA overhead is unpredictable, it's usually because the workflow lacks the structural governance to contain variance. Review volume fluctuates based on model performance on each new data batch. Escalations spike when edge cases cluster. Rework cycles lengthen timelines without warning. Costs end up being discovered rather than planned.
The organizational consequences extend beyond annotation. Model launches slip because the training data isn't ready. Procurement stakeholders lose confidence in annotation vendor estimates. Operations leaders find themselves managing annotation as a source of uncertainty rather than a reliable input to ML development. Founders managing scaling pressure can't make confident infrastructure investments when annotation costs are unpredictable.
Operational predictability is a leading indicator of workflow maturity. When QA costs and timelines are stable, it's because the underlying workflow is governed by defined rules rather than reactive decisions. Mindkosh places scalable workflow governance and operational visibility at the center of how annotation pipelines are designed — because annotation that can't be planned around reliably is annotation that's adding organizational friction, not just labeling data.
What mature AI-assisted annotation operations do differently
The seven signs above are symptoms. The underlying theme across all of them is the same: the workflow was designed for automation claims rather than operational maturity.
Mature annotation operations approach the problem differently at the design level.
They optimize review allocation instead of maximizing automation claims
The goal in a mature pipeline isn't to minimize the percentage of labels that go through any review — it's to ensure that human review is concentrated on cases where it adds genuine value. That means investing in confidence calibration, building sampling strategies that are actually responsive to model uncertainty, and designing reviewer workflows around judgment rather than confirmation.
They treat QA as a system design problem
QA in mature annotation workflows isn't an afterthought applied to the output of a labeling process. It's designed into the workflow from the start — with defined routing rules, escalation criteria, sampling strategies, and feedback mechanisms. The QA system is as much a product of deliberate design as the labeling process itself.
They continuously refine ontology, routing, and reviewer feedback loops
Static ontologies, static confidence thresholds, and static review policies are recipes for drift. Mature operations treat annotation as a continuously improving system — updating ontology definitions as edge cases surface, adjusting routing thresholds as model performance changes, and closing feedback loops so reviewer decisions actively improve future labeling.
How to evaluate whether your AI-assisted labeling workflow is truly scaling
If you've read this far and recognize several of these signs in your current workflow, the next step is a structured self-assessment. These questions are designed to surface the specific points where your pipeline may be absorbing friction rather than eliminating it.
Review coverage and allocation:
- What percentage of AI-generated labels require manual validation before they're accepted?
- Is your QA workload growing faster than your throughput, or is it stabilizing as volume increases?
- Are reviewers spending the majority of their time on genuinely uncertain labels, or on high-confidence outputs that rarely get changed?
Consistency and ontology:
- Are reviewer disagreement rates tracked and trending in a meaningful direction?
- When two reviewers reach different conclusions on the same label, is there a documented process for resolution and ontology update?
Edge cases and drift:
- Are the same categories of edge cases appearing in review queues repeatedly across batches?
- When batch-to-batch label quality is compared, is it stable, improving, or drifting?
Operational predictability:
- Can you forecast QA costs and annotation timelines within a reasonable confidence interval?
- When dataset volume doubles, does QA capacity need to scale proportionally?
If several of these questions surface genuine uncertainty or known problems, the workflow likely has structural inefficiencies worth addressing at the architecture level — not just by adding reviewers or adjusting individual policies.
That's typically where an annotation workflow audit becomes valuable: mapping where the QA overhead is actually entering the pipeline, identifying which structural mechanisms are absent or misconfigured, and designing toward operational stability rather than continuing to manage variance as it appears.

Conclusion
If your AI-assisted annotation pipeline still requires near-constant manual review, an expanding QA team, and repetitive validation cycles across every batch, the issue is rarely that AI-assisted annotation doesn't work. More often, it signals something more specific and more fixable: a workflow that was built for throughput claims rather than operational maturity.
The root issues are usually architectural — weak confidence calibration, absent routing logic, ontology gaps, closed-loop feedback mechanisms that were never built, QA policies designed by default rather than by design. These aren't exotic problems. They're common in annotation operations at almost every scale. And they're addressable when they're correctly identified.
If your annotation team is spending more time reviewing labels than accelerating throughput, the root issue is usually workflow architecture — not AI adoption. The seven signs above give you a starting point for diagnosing where the friction is entering your pipeline.
For some teams, that diagnosis leads to internal corrections — tightening confidence routing, closing feedback loops, shoring up ontology governance. This article gives you the framework to start that work.
For others, the workflow is complex enough — multi-modal data, sensor fusion, production-grade QC requirements — that rebuilding it internally isn't the right call. That's where a managed annotation service built for exactly this kind of complexity becomes the more practical path.
Mindkosh is a quality-first AI-powered annotation platform and managed service built for ML teams working with complex, multi-modal datasets — images, video, LiDAR, point clouds, depth, thermal, and more. Unlike generic labeling tools, Mindkosh embeds quality control throughout the workflow rather than bolting it on at the end, keeps humans firmly in the loop alongside AI-assisted automation, and gives clients full ownership and control of their data at every stage.
If your annotation pipeline needs a professional rebuild rather than a patch, we're here to help. Estimate annotation costs for multimodal AI datasets using our tool before you scale labeling operations, and see for yourself if there is a significant ROI gain.
Frequently asked questions
What is AI-assisted annotation?
AI-assisted annotation (also referred to as AI-assisted labeling) is a data labeling approach in which machine learning models generate initial label predictions for a dataset, and human reviewers validate, correct, or supplement those predictions. The goal is to reduce the time and cost of manual labeling by having AI handle high-confidence, repetitive cases while humans focus on ambiguous or low-confidence inputs. In a well-designed workflow, AI assistance substantially reduces manual effort without eliminating human judgment from the process.
What is AI-assisted labeling?
AI-assisted labeling refers to the same core process as AI-assisted annotation — using model-generated predictions to accelerate human labeling workflows. The terms are often used interchangeably. In practice, "labeling" tends to refer more to the classification or tagging of individual data points, while "annotation" can encompass a broader range of structured data markup tasks including segmentation, bounding box drawing, and transcription. Both rely on the same underlying workflow design principles: confident predictions flow through efficiently; uncertain or edge-case predictions receive proportionate human attention.
How much human QA is normal in AI-assisted annotation workflows?
There is no universal benchmark, as QA rates depend heavily on task complexity, model maturity, and data distribution. However, as a general operational guideline, mature AI-assisted workflows typically require targeted human review of 20–40% of outputs — concentrated on low-confidence predictions, class-boundary cases, and periodic quality sampling. Review rates consistently above 70–80% suggest that confidence routing is either absent or not functioning as intended, and that the workflow is operating more like a manual pipeline with an AI first pass than a genuinely hybrid system.
Why does manual QA still increase in AI-assisted pipelines?
Manual QA tends to expand in AI-assisted pipelines for several interconnected reasons: confidence scores are not calibrated well enough to be trusted for routing decisions; ontology definitions are ambiguous enough to create consistent reviewer disagreement; edge-case handling is reactive rather than structured; and feedback loops between reviewer decisions and model or ontology updates are weak or absent. Each of these issues compounds the others — weak calibration leads to blanket review policies, blanket review generates reviewer fatigue, reviewer fatigue reduces quality, and poor quality justifies more review. Addressing these problems requires workflow redesign rather than simply adding QA capacity.
Can AI-assisted labeling fully replace human reviewers?
Not in any annotation context where label quality has meaningful downstream consequences. Human review remains essential for resolving genuine ambiguity, handling novel inputs outside the model's training distribution, maintaining ontology governance, and catching systematic model errors before they propagate through training data. The goal of AI-assisted annotation is not to eliminate human reviewers but to concentrate their effort on the decisions where human judgment genuinely adds value — reducing the proportion of time spent on rote validation of high-confidence, clearly correct labels.
What causes annotation inconsistency at scale?
Annotation inconsistency at scale typically traces back to three sources: ontology gaps (unclear or incomplete definitions of label boundaries), weak reviewer alignment processes (reviewers making independent interpretations without calibration), and absent or slow feedback loops (reviewer decisions not flowing back to update the ontology or retrain the model). AI-assisted pipelines can amplify inconsistency when they're built on a weak ontology — because the model propagates whatever ambiguity exists in the training definitions across a high volume of predictions, and human reviewers then apply different interpretations when validating those predictions.
How do you reduce QA overhead in data annotation?
Reducing QA overhead effectively requires addressing it as a workflow design problem rather than a resourcing problem. The key levers are: calibrating confidence scoring so model predictions can be trusted operationally; building routing logic that directs low-confidence and edge-case predictions to reviewers while allowing high-confidence outputs to pass with targeted sampling; strengthening ontology governance to reduce reviewer disagreement; and closing feedback loops so reviewer decisions actively improve the model and ontology over time. Adding more reviewers without addressing these structural factors typically results in the QA overhead expanding proportionally with the team rather than declining.
What should companies evaluate in an annotation vendor?
Beyond the standard evaluation criteria around labeling accuracy and domain coverage, companies with serious annotation needs should assess: how the vendor handles confidence-based review routing; what their approach to ontology governance and versioning looks like; how reviewer disagreements are tracked and resolved; what mechanisms exist for detecting and correcting annotation drift across batches; and how well they can demonstrate operational predictability in cost and timeline forecasting at varying dataset volumes. An annotation vendor that can speak clearly to workflow design and QA system architecture — rather than only to labeling throughput and accuracy benchmarks — is significantly more likely to deliver sustainable results at scale.
Is your annotation team spending more time reviewing labels than accelerating throughput?
If any of the signs in this article reflect your current pipeline, the root issue is usually workflow architecture — not AI adoption. Mindkosh works with AI teams and operations leaders to design annotation workflows that reduce unnecessary QA overhead while maintaining quality at scale.
We don't lead with automation claims. We start with workflow design.
Talk to us for annotation needs of all shapes and sizes



